24 ✅ Raspagem de dados (Web scraping)
24.1 Introdução
Este capítulo faz a introdução do básico sobre raspagem de dados (web scraping) com o pacote rvest. Raspagem de dados é uma ferramenta muito útil para extração de dados de páginas web. Alguns websites oferecem uma API, um conjunto de requisições HTTP estruturadas que retornam dados no formato JSON, com o qual você pode lidar usando as técnicas do Capítulo 23. Sempre que possível, você deve usar uma API1, pois geralmente te retornará dados mais confiáveis. Entretanto, infelizmente, programar com APIs web está fora do escopo deste livro. Ao invés disso, ensinaremos sobre raspagem de dados, uma técnica que funciona independentemente de o site fornecer uma API ou não.
Neste capítulo, discutiremos primeiro sobre ética e legalidade da raspagem de dados antes de falar sobre o básico de HTML. Você aprenderá o básico sobre seletores CSS para localizar elementos específicos em uma página, e como usar funções do rvest para obter dados de textos e atributos de um HTML para o R. Depois, discutiremos algumas técnicas para descobrir qual seletor CSS você precisa para a página que está fazendo a raspagem de dados e terminaremos falando sobre alguns estudos de caso e uma breve discussão sobre websites dinâmicos.
24.1.1 Pré-requisitos
Neste capítulo, iremos focar nas ferramentas fornecidas pelo pacote rvest. O pacote rvest é um membro do tidyverse, mas não faz parte de seus componentes principais, portanto devemos carregá-lo explicitamente. Iremos também carregar o tidyverse completo, já que é geralmente muito útil para trabalhar com os dados obtidos da raspagem.
24.2 Ética e legalidade da raspagem de dados
Antes de começarmos a discutir o código que você precisará para efetuar a raspagem de dados, precisamos discutir se é ético e lícito realizá-la. No geral, a situação é complicada em relação a ambos.
A legislação depende muito de onde você vive. Entretanto, como princípio geral, se um dado é público, impessoal e factual, você provavelmente não terá problemas2. Esses três fatores são importantes porque estão ligados aos termos e condições do site, às informações de identificação pessoal e aos direitos autorais, como discutiremos a seguir.
Se os dados não forem públicos, impessoais ou factuais, ou se você estiver coletando os dados especificamente para ganhar dinheiro com eles, será necessário falar com um advogado. Em qualquer caso, você deve respeitar os recursos do servidor que hospeda as páginas em que você está efetuando a raspagem de dados. Mais importante ainda, isso significa que se você estiver fazendo raspagem de muitas páginas, certifique-se de esperar um pouco entre cada requisição. Um jeito fácil é utilizar o pacote polite de Dmytro Perepolkin. Ele fará uma pausa automatica entre as requisições e armazenará os resultados (cache) para que você não precise solicitar a mesma página duas vezes.
24.2.1 Termos de serviço
Se você olhar atentamente, descobrirá que muitos websites incluem em algum lugar da página um link para “termos e condições” ou “termos de serviço”, e se você ler a página atentamente, você geralmente descobrirá que o site especificamente proíbe sua raspagem de dados. Essas páginas tendem a ser uma terra sem lei, onde as empresas fazem reivindicações muito amplas. É educado respeitar estes termos de serviço sempre que possível, mas considere as reivindicações com cautela.
Os tribunais dos Estados Unidos concluíram que simplesmente colocar os termos de serviço no rodapé do website não é suficiente para que você fique vinculado a eles, e.x., HiQ Labs v. LinkedIn. Em geral, para que você seja submetido aos termos de serviços, você deve ter tido uma ação explícita, como criar uma conta ou marcar uma opção. Isto torna importante saber se um dado é público ou não; se você não precisa ter uma conta para acessá-lo, é improvável que você tenha qualquer vínculo com os termos de serviço. Note que a situação é diferente na Europa, onde os tribunais concluíram que os termos de serviços são aplicáveis mesmo que você não concorde explicitamente com eles.
24.2.2 Informações de identificação pessoal
Mesmo que o dado seja público, você deve ter extremo cuidado em fazer raspagem de informações pessoais como nomes, endereços de email, números telefônicos, datas de nascimento, etc. A Europa, em particular, tem leis bem restritas sobre coleta e armazenamento destes tipos de dados (GDPR), e independente de onde você viva, é provável que passe por complicações éticas. Por exemplo, em 2016, um grupo de pesquisadores rasparam dados públicos contendo informações pessoais (e.x., nomes de usuário, idade, genero, localização, etc.) sobre 70.000 pessoas do site de relacionamento OkCupid e eles liberaram publicamente estes dados sem qualquer tentativa de torná-los anônimos (anonymization). Enquanto os pesquisadores acharam que não havia nada de errado com isso, uma vez que os dados já eram públicos, este trabalho foi largamente condenado devido a preocupações éticas sobre a identificação dos usuários cuja informação foi liberada no conjunto de dados. Se seu trabalho envolve raspagem de dados de informações com identificação pessoal, nós recomendamos fortemente que você leia sobre o estudo do caso OkCupid3 bem como casos similares de estudos com éticas de pesquisa questionáveis envolvendo a aquisição e liberação de informações com idenficação pessoal.
24.2.3 Direitos autorais (copyright)
Finalmente, você também deve se preocupar com as leis de direitos autorais. As leis de direitos autorais são complicadas, mas vale a pena dar uma olhada na lei estadunidense que descreve exatamente o que é protegido: “[…] obras originais de autoria fixadas em qualquer meio de expressão tangível, […]”. Em seguida, descreve categorias específicas em que as leis se aplicam, como obras literárias, obras musicais, filmes e muito mais. Os dados estão notavelmente ausentes da proteção de direitos autorais. Isso significa que, desde que você limite sua raspagem de dados a fatos, a proteção de direitos autorais não se aplica. (Porém, observe que a Europa possui um direito separado “sui generis” que protege bases de dados (databases).)
Como um breve exemplo, nos Estados Unidos, listas de ingredientes e de instruções não estão sujeitas às leis de direitos autorais, portanto estas leis não podem ser usadas para proteger uma receita. Mas se esta lista de receitas estiver acompanhada de um conteúdo literário substancial, então ela poderá ser protegida. É por isso que quando você procura por uma receita na internet, ela é acompanhada de tanto conteúdo.
Se você realmente precisa fazer raspagem de dados de conteúdo original, (como texto ou imagem), você ainda pode estar protegido pela doutrina de uso justo (doctrine of fair use). O uso justo (fair use) não é uma regra rígida e rápida, mas pesa uma série de fatores. É mais provável que se aplique caso você esteja coletando dados para pesquisa ou para fins não comerciais e se limite a coletar apenas o que precisa.
24.3 O básico de HTML
Para fazer raspagem de dados em páginas web, você precisa primeiro entender um pouco sobre HTML, a linguagem usada para criar páginas web. HTML é abreviação HyperText Markup Language e se parece com algo deste tipo:
<html>
<head>
<title>Título da Página</title>
</head>
<body>
<h1 id='primeiro'>Um cabeçalho</h1>
<p>Algum texto & <b>algum texto em negrito.</b></p>
<img src='myimg.png' width='100' height='100'>
</body>HTML tem uma estrutura hierárquica formada por elementos que consiste em uma marcação (tag) de início (e.x., <tag>), opcionalmente um atributo (attributes) (id='primeiro'), e uma marcação de fim4 (como </tag>), e conteúdo (contents) (tudo entre a marcação de início e de fim).
Como < e > são usados para início e fim das marcações, você não pode escrevê-los diretamente. Ao invés disso, você deve usar os caracteres de fuga (escapes) > (maior que ou greater than) e < (menor que ou less than) do HTML. E como estas fugas usam &, se você quiser escrever o “&” (E comercial ou ampersand) deve usar a fuga &. Há uma grande variedade de caracteres de fuga no HTML, mas você não precisa se preocupar muito com isto, pois o rvest lida automaticamente com elas para você.
A raspagem de dados é possível porque a maioria das páginas que contém o dado que você quer extrair geralmente possuem uma estrutura consistente.
24.3.1 Elementos
Existem mais de 100 elementos HTML. Alguns dos mais importantes são:
Toda página HTML deve estar entre um elemento
<html>, que deve ter dois elementos descendentes (children):<head>, que contém metadados como título da página, e<body>, que tem o conteúdo que você vê através do navegador (browser).Marcações de bloco (block) como
<h1>(cabeçalho 1 ou heading 1),<section>(seção ou section),<p>(parágrafo ou paragraph), e<ol>(lista ordenada ou ordered list) formam a estrutura geral da página.Marcações em linha (inline) como
<b>(negrito ou bold),<i>(itálico ou italics), e<a>(link) formatam o texto dentro das marcações de bloco.
Se você encontrar uma marcação que nunca viu antes, você pode pesquisar o que ela faz usando a pesquisa do Google. Um outro ótimo lugar para começar é o MDN Web Docs que descreve todos os aspectos da programação web.
A maioria dos elementos podem ter conteúdo entre suas marcações de início e fim. Este conteúdo pode ser um texto ou outros elementos. Por exemplo, o HTML a seguir contém um parágrafo de texto com uma palavra em negrito.
<p>
Olá! Meu <b>nome</b> é Hadley.
</p>Os descendentes (children) são os elementos contidos em outro, portanto, o elemento <p> acima possui um descendente, o elemento <b>. O elemento <b> não possui descendentes, porém ele tem conteúdo (o texto “nome”).
24.3.2 Atributos
Marcações podem ter atributos (attributes) com nomes que se parecem com nome1='valor1' nome2='valor2'. Dois dos mais importantes atributos são id e class, que são usados juntamente com as folhas de estilo CSS (Cascading Style Sheets) para controlar a aparência visual da página. Eles são muito úteis quando raspamos dados de uma página. Atributos também são usados para gravar os destinos dos links (o atributo href do elemento <a>) e a origem de imagens (o atributo src do elemento <img>).
24.4 Extraindo dados
Para começar com a raspagem de dados, você precisará do endereço (URL) da página que deseja fazer a raspagem, a qual normalmente pode ser copiada do seu navegador. Você precisará então importar o HTML daquela página para o R com read_html(). Esta função retorna um objeto xml_document5 que você então irá manipular usando as funções do rvest:
html <- read_html("http://rvest.tidyverse.org/")
html
#> {html_document}
#> <html lang="en">
#> [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UT ...
#> [2] <body>\n <a href="#container" class="visually-hidden-focusable">Ski ...rvest também possui uma função que te permite criar um HTML (inline). Usaremos muito isso neste capítulo conforme ensinamos várias funções do rvest com exemplos simples.
html <- minimal_html("
<p>Este é um parágrafo</p>
<ul>
<li>Esta é uma lista com marcadores</li>
</ul>
")
html
#> {html_document}
#> <html>
#> [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UT ...
#> [2] <body>\n<p>Este é um parágrafo</p>\n <ul>\n<li>Esta é uma lista com m ...Agora que você tem o HTML no R, é hora de extrair os dados de interesse. Você aprenderá primeiro sobre seletores CSS, os quais permitem que você identifique elementos de interesse e sobre as funções do rvest que permitem que você extraia dados desses elementos. Depois, falaremos brevemente sobre tabelas HTML, que possuem algumas ferramentas especiais.
24.4.1 Encontrando elementos
CSS é a abreviação para “folha de estilo em cascata” (cascading style sheets), que é uma ferramenta para definir os estilos visuais dos documentos HTML. CSS inclui uma pequena linguagem chamada seletores CSS (CSS Selectors) para seleção de elementos em uma página. Seletores CSS definem padrões para localizar elementos HTML e são úteis para raspagem de dados, pois definem uma forma concisa de descrever o elemento do qual você quer extrair os dados.
Retornaremos aos seletores CSS em mais detalhes na Seção 24.5, mas felizmente você já pode percorrer um bom caminho com apenas três seletores:
pseleciona todos elementos<p>..tituloseleciona todos elementos comclass“titulo”.#tituloseleciona os elemento com o atributoidigual a “titulo”. Atributos Id devem ser únicos dentro de um documento HTML, portanto isto sempre retornará apenas um elemento.
Vamos testar estes seletores com um exemplo simples:
html <- minimal_html("
<h1>Isto é um cabeçalho</h1>
<p id='primeiro'>Isto é um parágrafo</p>
<p class='importante'>Isto é um parágrafo importante</p>
")Use html_elements() para encontrar todos os elementos que correspondem ao seletor:
html |> html_elements("p")
#> {xml_nodeset (2)}
#> [1] <p id="primeiro">Isto é um parágrafo</p>
#> [2] <p class="importante">Isto é um parágrafo importante</p>
html |> html_elements(".importante")
#> {xml_nodeset (1)}
#> [1] <p class="importante">Isto é um parágrafo importante</p>
html |> html_elements("#primeiro")
#> {xml_nodeset (1)}
#> [1] <p id="primeiro">Isto é um parágrafo</p>Outra função importante é a html_element() que sempre retorna o mesmo número de saídas que entradas. Se você a usar no documento inteiro, ela retornará a primeira correspondência:
html |> html_element("p")
#> {html_node}
#> <p id="primeiro">Há uma diferença importante entre html_element() e html_elements() quando você usa um seletor que não corresponde a nenhum elemento. html_elements() retorna um vetor de tamanho 0, enquanto html_element() retorna um valor faltante (missing value). Esta diferença será muito importante em breve.
html |> html_elements("b")
#> {xml_nodeset (0)}
html |> html_element("b")
#> {xml_missing}
#> <NA>24.4.2 Seleções aninhadas (nesting)
Na maioria das vezes, você usará html_elements() e html_element() juntas, geralmente usando html_elements() para identificar elementos que virão com várias observações e então usar html_element() para identificar elementos que se tornarão variáveis. Vamos ver isso em ação com um exemplo simples. Aqui temos uma lista não ordenada (<ul>) onde cada item da lista (<li>) contém alguma informação sobre quatro personagens de Guerra nas Estrelas (StarWars):
html <- minimal_html("
<ul>
<li><b>C-3PO</b> é um <i>robô</i> que pesa <span class='weight'>167 kg</span></li>
<li><b>R4-P17</b> é um <i>robô</i></li>
<li><b>R2-D2</b> é um <i>robô</i> que pesa <span class='weight'>96 kg</span></li>
<li><b>Yoda</b> pesa <span class='peso'>66 kg</span></li>
</ul>
")Podemos usar html_elements() para criar um vetor onde cada elemento corresponde a um personagem diferente:
personagens <- html |> html_elements("li")
personagens
#> {xml_nodeset (4)}
#> [1] <li>\n<b>C-3PO</b> é um <i>robô</i> que pesa <span class="weight">167 ...
#> [2] <li>\n<b>R4-P17</b> é um <i>robô</i>\n</li>
#> [3] <li>\n<b>R2-D2</b> é um <i>robô</i> que pesa <span class="weight">96 k ...
#> [4] <li>\n<b>Yoda</b> pesa <span class="peso">66 kg</span>\n</li>Para extrair o nome de cada personagem, usamos html_element(), pois quando aplicada à saída da html_elements() é garantido retornar uma resposta por elemento:
personagens |> html_element("b")
#> {xml_nodeset (4)}
#> [1] <b>C-3PO</b>
#> [2] <b>R4-P17</b>
#> [3] <b>R2-D2</b>
#> [4] <b>Yoda</b>A diferença entre html_element() e html_elements() não é importante para o nome, mas é importante para o peso. Queremos ter um peso para cada personagem, até mesmo quando não há <span> peso. Isto é o que html_element() faz:
personagens |> html_element(".peso")
#> {xml_nodeset (4)}
#> [1] NA
#> [2] NA
#> [3] NA
#> [4] <span class="peso">66 kg</span>html_elements() encontra todos os <span>s peso que são descendentes de personagens. Existem apenas três deles, então perdemos a conexão entre os nomes e os pesos:
personagens |> html_elements(".peso")
#> {xml_nodeset (1)}
#> [1] <span class="peso">66 kg</span>Agora que você selecionou os elementos de interesse, você precisa extrair os dados, sejam do conteúdo texto quanto de alguns atributos.
24.4.3 Textos e atributos
html_text2()6 extrai o texto puro de um elemento HTML:
personagens |>
html_element("b") |>
html_text2()
#> [1] "C-3PO" "R4-P17" "R2-D2" "Yoda"
personagens |>
html_element(".peso") |>
html_text2()
#> [1] NA NA NA "66 kg"Observe que qualquer caractere de fuga é automaticamente endereçado; você apenas verá estes caracteres no código fonte HTML, mas não nos dados retornados pelo rvest.
html_attr() extrai dados dos atributos:
html <- minimal_html("
<p><a href='https://en.wikipedia.org/wiki/Cat'>gatos</a></p>
<p><a href='https://en.wikipedia.org/wiki/Dog'>cães</a></p>
")
html |>
html_elements("p") |>
html_element("a") |>
html_attr("href")
#> [1] "https://en.wikipedia.org/wiki/Cat" "https://en.wikipedia.org/wiki/Dog"html_attr() sempre retorna uma string, portanto, se você está extraindo números ou datas, você precisará fazer algum processamento posterior.
24.4.4 Tabelas
Se você estiver com sorte, seus dados já estarão armazenados em uma tabela HTML, portanto, é apenas uma questão de lê-los diretamenta desta tabela. Geralmente é muito fácil reconhecer uma tabela em seu navegador: ela terá uma estrutura retangular de linhas e colunas e você pode copiar e colar em uma ferramenta como o Excel.
Tabelas HTML são constituídas por quatro elementos principais: <table>, <tr> (linha da tabela), <th> (cabeçalho da tabela), e <td> (dado da tabela). Aqui está uma tabela HTML simples com duas colunas e três linhas:
html <- minimal_html("
<table class='minha_tabela'>
<tr><th>x</th> <th>y</th></tr>
<tr><td>1.5</td> <td>2.7</td></tr>
<tr><td>4.9</td> <td>1.3</td></tr>
<tr><td>7.2</td> <td>8.1</td></tr>
</table>
")rvest fornece uma função que sabe como ler este tipo de dado: html_table(). Ela retorna uma lista contendo um tibble para cada tabela encontrada na página. Use html_element() para identificar a tabela que deseja extrair:
html |>
html_element(".minha_tabela") |>
html_table()
#> # A tibble: 3 × 2
#> x y
#> <dbl> <dbl>
#> 1 1.5 2.7
#> 2 4.9 1.3
#> 3 7.2 8.1Note que x e y foram automaticamente convertidos para números. Esta conversão automática nem sempre funciona bem, portanto, em cenários mais complexos você deve querer desligá-la com convert = FALSE e então fazer sua própria conversão.
24.5 Encontrando os seletores adequados
Descobrir o seletor que você precisa para seus dados é geralmente a parte mais difícil do problema. Você geralmente deverá fazer alguns experimentos para encontrar um seletor que seja ao mesmo tempo específico (e.x. ele não seleciona algo que não interessa) e sensível (e.x. ele seleciona tudo que interessa). Tentativa e erro é parte normal do processo! Existem duas principais ferramentas disponíveis para te ajudar com este processo: SelectorGadget e as Ferramentas do Desenvolvedor de seu navegador.
SelectorGadget é um aplicativo (bookmarklet) javascript que gera seletores automaticamente baseado em exemplos negativos e positivos fornecidos por você. Ele nem sempre funciona, mas quando o faz, é uma mágica! Você pode aprender a instalar e usar o SelectorGadget lendo https://rvest.tidyverse.org/articles/selectorgadget.html ou assistindo o video de Mine em https://www.youtube.com/watch?v=PetWV5g1Xsc.
Todo navegador moderno vem com um kit de ferramentas para desenvolvedores, mas recomendamos o Chrome, mesmo que não seja seu navegador padrão: suas ferramentas para desenvolvedores web são algumas das melhores e estão imediatamente disponíveis. Clique com o botão direito em um elemento da página e clique Inspecionar. Isto abrirá uma visão expandida da página HTML completa, centralizando o elemento que você acabou de clicar. Você pode usar isto para explorar a página e ter uma ideia de quais seletores podem funcionar. Preste atenção aos atributos class e id, uma vez que geralmente são usados para formar a estrutura visual da página, e portanto, são boas ferramentas para extrair os dados que você está procurando.
Dentro do menu Elementos, você também pode clicar com o botão direito em um elemento e selecionar Copiar como Seletor para gerar um seletor que identificará de forma única o elemento de interesse.
Caso o SelectorGadget ou as Ferramentas do Desenvolvedor (DevTools) do Chrome* gerarem um seletor CSS que você não entende, tente Seletores Explicados (Selectors Explained) que traduz seletores CSS para inglês básico. Caso você se encontre fazendo isso muitas vezes, você pode querer aprender mais sobre seletores CSS em geral. Recomendamos começar com o engraçado tutorial jantar CSS e então conferir o MDN web docs.
24.6 Juntando tudo
Vamos juntar tudo isso e fazer a raspagem de dados de alguns websites. Há algum risco destes exemplos não funcionarem mais quando você executá-los — este é o desafio fundamental da raspagem de dados; se a estrutura do site muda, então você terá que mudar seu código de raspagem.
24.6.1 Guerra nas Estrelas (StarWars)
rvest inclui um simples exemplo na vignette("starwars"). Esta é uma página simples com o mínimo de HTML, portanto, é um bom lugar para se começar. Eu encorajo você a navegar até essa página agora e usar “Inspecionar Elemento” para inspecionar um dos cabeçalhos que tem o título de um filme de Guerra nas Estrelas. Use o teclado ou o mouse para explorar a hierarquia do HTML e veja se consegue ter uma noção da estrutura compartilhada de cada filme.
Você deve conseguir ver que cada filme possui uma estrutura compartilhada que se parece com isto:
<section>
<h2 data-id="1">The Phantom Menace</h2>
<p>Released: 1999-05-19</p>
<p>Director: <span class="director">George Lucas</span></p>
<div class="crawl">
<p>...</p>
<p>...</p>
<p>...</p>
</div>
</section>Nossa meta é transformar isto em um data frame com 7 linhas e as variáveis titulo, data_lancamento, diretor, e introducao. Começaremos lendo o HTML e extraindo todos os elementos <section>:
url <- "https://rvest.tidyverse.org/articles/starwars.html"
html <- read_html(url)
secao <- html |> html_elements("section")
secao
#> {xml_nodeset (7)}
#> [1] <section><h2 data-id="1">\nThe Phantom Menace\n</h2>\n<p>\nReleased: 1 ...
#> [2] <section><h2 data-id="2">\nAttack of the Clones\n</h2>\n<p>\nReleased: ...
#> [3] <section><h2 data-id="3">\nRevenge of the Sith\n</h2>\n<p>\nReleased: ...
#> [4] <section><h2 data-id="4">\nA New Hope\n</h2>\n<p>\nReleased: 1977-05-2 ...
#> [5] <section><h2 data-id="5">\nThe Empire Strikes Back\n</h2>\n<p>\nReleas ...
#> [6] <section><h2 data-id="6">\nReturn of the Jedi\n</h2>\n<p>\nReleased: 1 ...
#> [7] <section><h2 data-id="7">\nThe Force Awakens\n</h2>\n<p>\nReleased: 20 ...Isto retorna sete elementos que correspondem aos sete filmes encontrados na página, sugerindo que usar section como seletor é bom. Extrair cada elemento é direto, já que o dado está sempre presente no texto. É simplesmente uma questão de encontrar o seletor correto:
secao |> html_element("h2") |> html_text2()
#> [1] "The Phantom Menace" "Attack of the Clones"
#> [3] "Revenge of the Sith" "A New Hope"
#> [5] "The Empire Strikes Back" "Return of the Jedi"
#> [7] "The Force Awakens"
secao |> html_element(".director") |> html_text2()
#> [1] "George Lucas" "George Lucas" "George Lucas"
#> [4] "George Lucas" "Irvin Kershner" "Richard Marquand"
#> [7] "J. J. Abrams"Uma vez feito isso para cada componente, podemos encapsular todo o resultado em um tibble:
tibble(
titulo = secao |>
html_element("h2") |>
html_text2(),
data_lancamento = secao |>
html_element("p") |>
html_text2() |>
str_remove("Released: ") |>
parse_date(),
diretor = secao |>
html_element(".director") |>
html_text2(),
introducao = secao |>
html_element(".crawl") |>
html_text2()
)
#> # A tibble: 7 × 4
#> titulo data_lancamento diretor introducao
#> <chr> <date> <chr> <chr>
#> 1 The Phantom Menace 1999-05-19 George Lucas "Turmoil has engu…
#> 2 Attack of the Clones 2002-05-16 George Lucas "There is unrest …
#> 3 Revenge of the Sith 2005-05-19 George Lucas "War! The Republi…
#> 4 A New Hope 1977-05-25 George Lucas "It is a period o…
#> 5 The Empire Strikes Back 1980-05-17 Irvin Kershner "It is a dark tim…
#> 6 Return of the Jedi 1983-05-25 Richard Marquand "Luke Skywalker h…
#> # ℹ 1 more rowNós processamos um pouco mais a data_lancamento para obter uma variável que será mais fácil de usar depois em nossas análises.
24.6.2 Melhores filmes IMDB
Para nossa próxima tarefa, abordaremos algo um pouco mais complicado, extraindo os 250 melhores filmes da base de dados da Internet (IMDb). Quando este capítulo foi escrito, a página se parecia com a Figura 24.1.
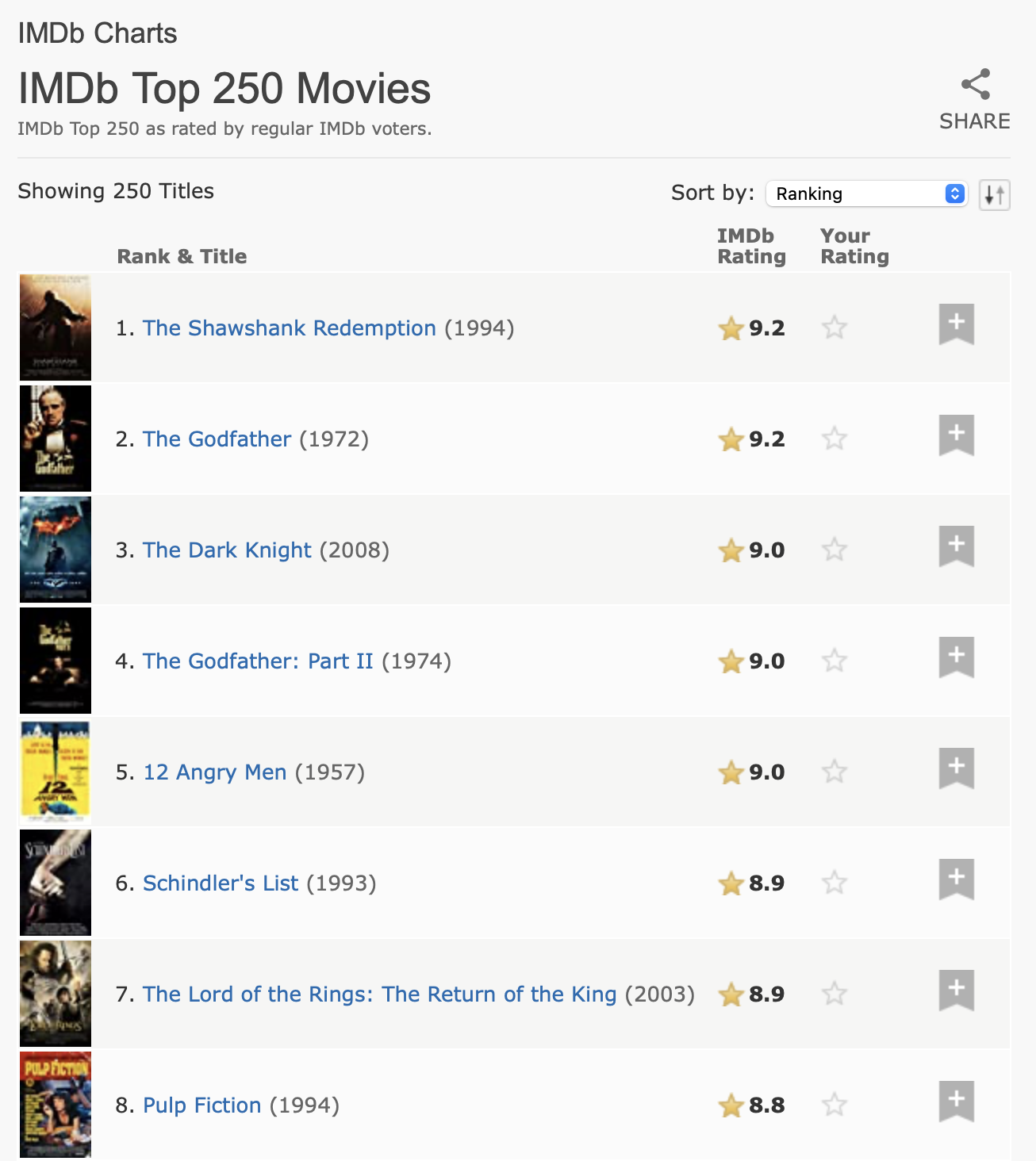
Este dados têm uma clara estrutura tabular, então vale a pena começar com html_table():
url <- "https://web.archive.org/web/20220201012049/https://www.imdb.com/chart/top/"
html <- read_html(url)
tabela <- html |>
html_element("table") |>
html_table()
tabela
#> # A tibble: 250 × 5
#> `` `Rank & Title` `IMDb Rating` `Your Rating` ``
#> <lgl> <chr> <dbl> <chr> <lgl>
#> 1 NA "1.\n The Shawshank Redempt… 9.2 "12345678910\n… NA
#> 2 NA "2.\n The Godfather\n … 9.1 "12345678910\n… NA
#> 3 NA "3.\n The Godfather: Part I… 9 "12345678910\n… NA
#> 4 NA "4.\n The Dark Knight\n … 9 "12345678910\n… NA
#> 5 NA "5.\n 12 Angry Men\n … 8.9 "12345678910\n… NA
#> 6 NA "6.\n Schindler's List\n … 8.9 "12345678910\n… NA
#> # ℹ 244 more rowsIsto inclui algumas colunas vazias, mas no geral, faz um bom trabalho ao capturar as informações da tabela. No entanto, precisamos fazer mais alguns processamentos para torná-la mais fácil de usar. Primeiro, renomearemos as colunas para facilitar o trabalho e removeremos os espaços em branco estranhos na classificação (rank) e no título (title). Faremos isto com select() (ao invés de rename()) para renomear e selecionar apenas essas duas colunas em uma única etapa. Em seguida, removeremos as novas linhas e espaços extras e usaremos separate_wider_regex() (da Seção 15.3.4) para extrair o título, ano e classificação em suas próprias variáveis.
classificacao <- tabela |>
select(
classificacao_titulo_ano = `Rank & Title`,
nota_imdb = `IMDb Rating`
) |>
mutate(
classificacao_titulo_ano = str_replace_all(classificacao_titulo_ano, "\n +", " ")
) |>
separate_wider_regex(
classificacao_titulo_ano,
patterns = c(
classificacao = "\\d+", "\\. ",
titulo = ".+", " +\\(",
ano = "\\d+", "\\)"
)
)
classificacao
#> # A tibble: 250 × 4
#> classificacao titulo ano nota_imdb
#> <chr> <chr> <chr> <dbl>
#> 1 1 The Shawshank Redemption 1994 9.2
#> 2 2 The Godfather 1972 9.1
#> 3 3 The Godfather: Part II 1974 9
#> 4 4 The Dark Knight 2008 9
#> 5 5 12 Angry Men 1957 8.9
#> 6 6 Schindler's List 1993 8.9
#> # ℹ 244 more rowsMesmo neste caso, em que a maioria dos dados vêm de células de tabela, ainda vale a pena dar uma olhada no HTML bruto. Se você fizer isso, descobrirá que podemos adicionar alguns dados extras usando um dos atributos. Esse é um dos motivos pelos quais vale a pena gastar um pouco de tempo explorando o código fonte da página; você pode encontrar dados extras ou uma rota de análise um pouco mais fácil.
html |>
html_elements("td strong") |>
head() |>
html_attr("title")
#> [1] "9.2 based on 2,536,415 user ratings"
#> [2] "9.1 based on 1,745,675 user ratings"
#> [3] "9.0 based on 1,211,032 user ratings"
#> [4] "9.0 based on 2,486,931 user ratings"
#> [5] "8.9 based on 749,563 user ratings"
#> [6] "8.9 based on 1,295,705 user ratings"Podemos combinar isto com os dados tabulares e aplicar novamente separate_wider_regex() para extrair os dados que nos interessam:
classificacao |>
mutate(
classificacao_n = html |> html_elements("td strong") |> html_attr("title")
) |>
separate_wider_regex(
classificacao_n,
patterns = c(
"[0-9.]+ based on ",
numero_usuarios = "[0-9,]+",
" user ratings"
)
) |>
mutate(
numero_usuarios = parse_number(numero_usuarios)
)
#> # A tibble: 250 × 5
#> classificacao titulo ano nota_imdb numero_usuarios
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 1 The Shawshank Redemption 1994 9.2 2536415
#> 2 2 The Godfather 1972 9.1 1745675
#> 3 3 The Godfather: Part II 1974 9 1211032
#> 4 4 The Dark Knight 2008 9 2486931
#> 5 5 12 Angry Men 1957 8.9 749563
#> 6 6 Schindler's List 1993 8.9 1295705
#> # ℹ 244 more rows24.7 Sites dinâmicos
Até agora nos concentramos em sites onde html_elements() retorna o que você vê no navegador e discutimos como processar o que ele retorna e como organizar essas informações em um data frame. Entretanto, algumas vezes você chegará a um site onde html_elements() e companhia não retornam nada parecido com o que você vê no navegador. Em muitos casos, isso ocorre porque você está tentando raspar dados de um site que gera dinamicamente o conteúdo da página com javascript. Atualmente, isso não funciona com o rvest, porque o rvest baixa o HTML bruto e não executa nenhum javascript.
Ainda assim é possível raspar os dados desses tipos de sites, mas o rvest precisa usar um processo mais caro: simular totalmente o navegador da web, incluindo a execução de todo javascript. Esta funcionalidade não estava disponível quando escrevemos este livro, mas é algo em que estamos trabalhando ativamente e pode estar disponível quando você ler isto. Ele usa o pacote chromote que, na verdade, executa um navegador Chrome em segundo plano e oferece ferramentas adicionais para interação com o site, como se fosse uma pessoa digitando o texto ou clicando em botões. Veja maiores informações sobre isto no website do rvest.
24.8 Resumo
Neste capítulo, você aprendeu sobre o porquê, o porque não e como fazer raspagem de dados em páginas da web. Primeiro, você aprendeu sobre o básico de HTML e como usar seletores CSS para se referir a elementos específicos, depois aprendeu como usar o pacote rvest para transferir dados do HTML para o R. Em seguida, demonstramos a raspagem de dados em dois estudos de caso: um cenário mais simples de raspagem de dados do site do pacote rvest com filmes de “Guerra nas Estrelas” e um cenário mais complexo de extração de dados dos 250 melhores filmes do IMDB.
Os detalhes técnicos da raspagem de dados da web podem ser complexos, especialmente quando se trata de sites, mas as considerações legais e éticas podem ser ainda mais complexas. É importante que você se informe sobre ambos antes de começar a coletar dados.
Isso nos leva ao final da parte de importação do livro, onde você aprendeu técnicas para obter dados de onde eles residem (planilhas, bancos de dados, arquivos JSON e websites) em um formato organizado (tidy) para o R. Agora é hora de voltarmos para um novo tópico: aproveitar ao máximo do R como linguagem de programação.
Muitas APIs populares já possuem um pacote no CRAN que as encapsulam, então comece sempre fazendo uma pesquisa antes!↩︎
Obviamente não somos advogados, e este não é um aconselhamento jurídico. Mas este é o melhor resumo que podemos dar depois de ler muito sobre esse assunto.↩︎
Um exemplo de artigo sobre o estudo do OkCupid foi publicado pela Wired, https://www.wired.com/2016/05/okcupid-study-reveals-perils-big-data-science.↩︎
Em várias marcações (incluindo
<p>e<li>) a marcação de fim não é obrigatória, mas acreditamos ser melhor incluí-la, pois torna a visualização da estrutura HTML mais fácil.↩︎Esta classe vem do pacote xml2. xml2 é um pacote de baixo nível a partir do qual o rvest foi criado.↩︎
rvest também fornece
html_text(), porém você deve usar quase semprehtml_text2(), já que esta faz um trabalho melhor ao converter HTML anihadas em texto.↩︎