19 ✅ Uniões (joins)
19.1 Introdução
É raro que uma análise de dados envolva apenas um único data frame. Normalmente você tem muitos quadros de dados e deve uní-los (joins) para responder às perguntas de seu interesse. Este capítulo apresentará dois tipos importantes de uniões (joins):
- Uniões de mutação (mutating joins), que adicionam novas variáveis a um data frame a partir de observações correspondentes em outro.
- Uniões de filtragem (filtering joins), que filtram observações de um data frame com base na correspondência ou não com uma observação em outro.
Começaremos discutindo as chaves (keys), as variáveis usadas para conectar um par de data frames através de uma união. Consolidamos a teoria com examinando as chaves (keys) no conjuntos de dados do pacote dados e, em seguida, usamos esse conhecimento para começar a unir os data frames. A seguir discutiremos como funcionam as uniões (joins), focando em sua ação nas linhas. Terminaremos com uma discussão sobre uniões não-equivalentes (non-equi joins), uma família de uniões que fornece uma maneira mais flexível de combinar chaves (keys) do que o relacionamento de igualdade padrão.
19.1.1 Pré-requisitos
Neste capítulo, exploraremos os cinco conjuntos de dados relacionados do pacote nycflights131 usando as funções de união do pacote dplyr.
19.2 Chaves (keys)
Para entender as uniões (joins), primeiro você precisa entender como duas tabelas podem ser conectadas por meio de um par de chaves (keys), dentro de cada tabela. Nesta seção, você aprenderá sobre os dois tipos de chave e verá exemplos de ambos nos conjuntos de dados do pacote nycflights13. Você também aprenderá como verificar se suas chaves são válidas e o que fazer se sua tabela não tiver uma chave.
19.2.1 Chaves primárias e chaves estrangeiras
Cada união (join) envolve um par de chaves (key): uma chave primária (primary key) e uma chave estrangeira (foreign key). Uma chave primária é uma variável ou conjunto de variáveis que identifica exclusivamente cada observação. Quando são necessárias mais de uma variável, a chave é denominada de chave primária composta (compound primary key). Por exemplo, no pacote dados:
-
companhias_aereasregistra dois dados sobre cada companhia aérea: seu código e seu nome completo. Você pode identificar uma companhia aérea com seu código de transportadora de duas letras, tornandocompanhia_aereaa chave primária (primary key).companhias_aereas #> # A tibble: 16 × 2 #> companhia_aerea nome #> <chr> <chr> #> 1 9E Endeavor Air Inc. #> 2 AA American Airlines Inc. #> 3 AS Alaska Airlines Inc. #> 4 B6 JetBlue Airways #> 5 DL Delta Air Lines Inc. #> 6 EV ExpressJet Airlines Inc. #> # ℹ 10 more rows -
aeroportosregistra dados sobre cada aeroporto. Você pode identificar cada aeroporto pelo seu código de aeroporto de três letras, tornandocodigo_aeroportoa chave primária.aeroportos #> # A tibble: 1,458 × 8 #> codigo_aeroporto nome latitude longitude altura #> <chr> <chr> <dbl> <dbl> <dbl> #> 1 04G Lansdowne Airport 41.1 -80.6 1044 #> 2 06A Moton Field Municipal… 32.5 -85.7 264 #> 3 06C Schaumburg Regional 42.0 -88.1 801 #> 4 06N Randall Airport 41.4 -74.4 523 #> 5 09J Jekyll Island Airport 31.1 -81.4 11 #> 6 0A9 Elizabethton Municipa… 36.4 -82.2 1593 #> # ℹ 1,452 more rows #> # ℹ 3 more variables: fuso_horario <dbl>, horario_verao <chr>, … -
avioesregistra dados sobre cada aeronave. Você pode identificar um avião pelo seu número de cauda, tornandocodigo_caudaa chave primária.avioes #> # A tibble: 3,322 × 9 #> codigo_cauda ano tipo fabricante modelo #> <chr> <int> <chr> <chr> <chr> #> 1 N10156 2004 Ala fixa multimotor EMBRAER EMB-145XR #> 2 N102UW 1998 Ala fixa multimotor AIRBUS INDUSTRIE A320-214 #> 3 N103US 1999 Ala fixa multimotor AIRBUS INDUSTRIE A320-214 #> 4 N104UW 1999 Ala fixa multimotor AIRBUS INDUSTRIE A320-214 #> 5 N10575 2002 Ala fixa multimotor EMBRAER EMB-145LR #> 6 N105UW 1999 Ala fixa multimotor AIRBUS INDUSTRIE A320-214 #> # ℹ 3,316 more rows #> # ℹ 4 more variables: motores <int>, assentos <int>, … -
climaregistra dados sobre o clima nos aeroportos de origem. Você pode identificar cada observação pela combinação de localização (origem do aeroporto) e horário, tornandoorigemedata_horaa chave primária composta (compound primary key).clima #> # A tibble: 26,115 × 15 #> origem ano mes dia hora temperatura ponto_condensacao #> <chr> <int> <int> <int> <int> <dbl> <dbl> #> 1 EWR 2013 1 1 1 39.0 26.1 #> 2 EWR 2013 1 1 2 39.0 27.0 #> 3 EWR 2013 1 1 3 39.0 28.0 #> 4 EWR 2013 1 1 4 39.9 28.0 #> 5 EWR 2013 1 1 5 39.0 28.0 #> 6 EWR 2013 1 1 6 37.9 28.0 #> # ℹ 26,109 more rows #> # ℹ 8 more variables: umidade <dbl>, direcao_vento <dbl>, …
Uma chave estrangeira (foreign key) é uma variável (ou conjunto de variáveis) que corresponde a uma chave primária em outra tabela. Por exemplo:
-
voos$codigo_caudaé uma chave estrangeira que corresponde à chave primáriaavioes$codigo_cauda. -
voos$companhia_aereaé uma chave estrangeira que corresponde à chave primáriacompanhias_aereas$companhia_aerea. -
voos$origemé uma chave estrangeira que corresponde à chave primáriaaeroportos$codigo_aeroporto. -
voos$destinoé uma chave estrangeira que corresponde à chave primáriaaeroportos$codigo_aeroporto. -
voos$origem-voos$data_horaé uma chave estrangeira composta que corresponde à chave primária compostaclima$origem-clima$data_hora.
Estes relacionamentos estão resumidos visualmente na Figura 19.1.
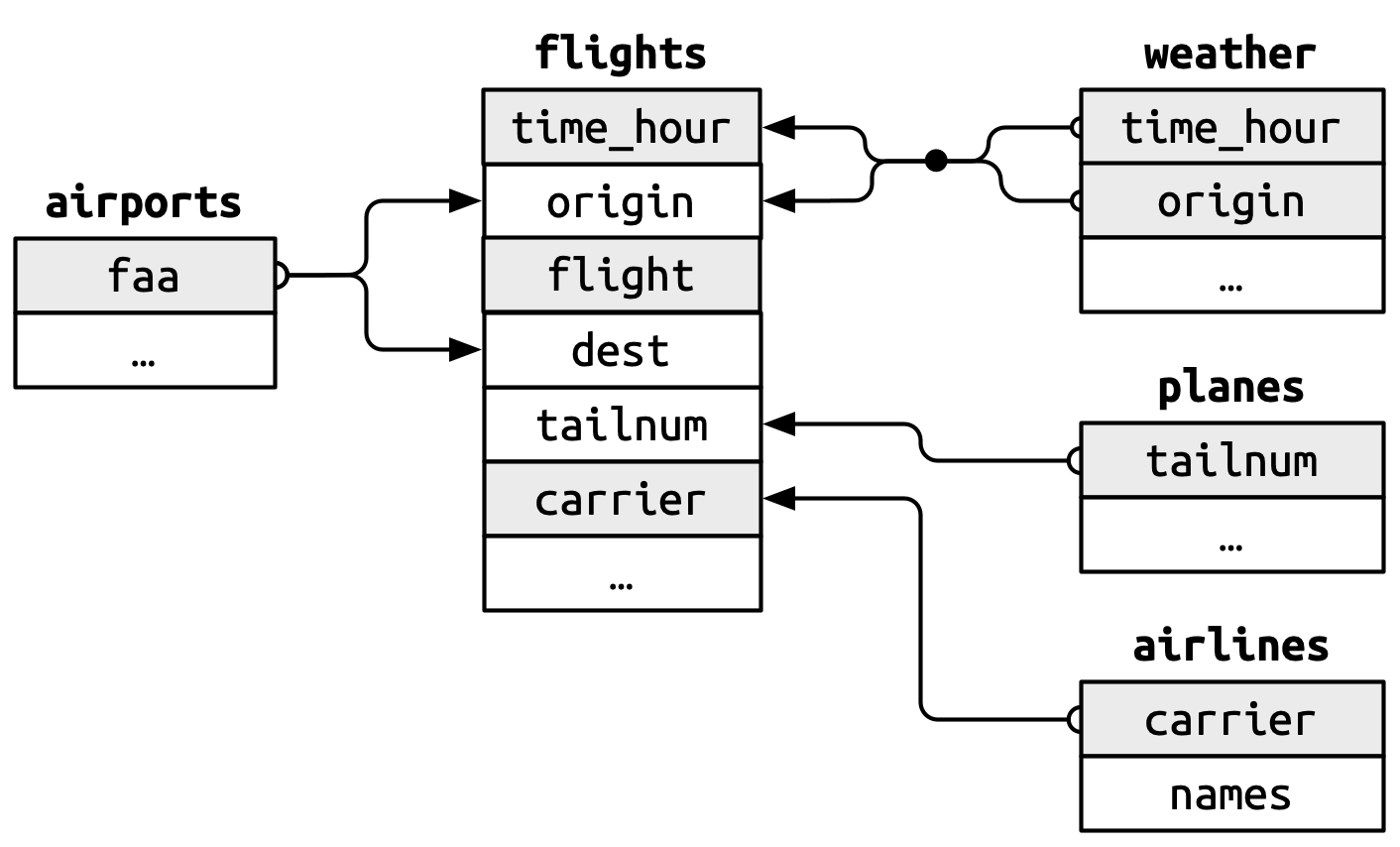
Você notará um recurso interessante no design dessas chaves: as chaves primária (primary key) e estrangeira (foreign key) quase sempre têm os mesmos nomes, o que, como você verá em breve, tornará sua vida para as uniões (joins) muito mais fácil. Também vale a pena notar a relação oposta: quase todos os nomes de variáveis usados em múltiplas tabelas têm o mesmo significado em cada lugar. Há apenas uma exceção: ano significa ano de partida em voos e ano de fabricação em avioes. Isso se tornará importante quando começarmos a unir as tabelas.
19.2.2 Verificando chaves primárias
Agora que identificamos as chaves primárias em cada tabela, é uma boa prática verificar se elas realmente identificam cada observação de forma única. Uma maneira de fazer isso é contar com a função count() as chaves primárias e procurar entradas onde n é maior que um. Isso revela que aviões e clima parecem bons:
Você também deve verificar se há valores ausentes (missing values) em suas chaves primárias – se um valor estiver faltando, ele não poderá identificar uma observação!
avioes |>
filter(is.na(codigo_cauda))
#> # A tibble: 0 × 9
#> # ℹ 9 variables: codigo_cauda <chr>, ano <int>, tipo <chr>,
#> # fabricante <chr>, modelo <chr>, motores <int>, assentos <int>, …
clima |>
filter(is.na(data_hora) | is.na(origem))
#> # A tibble: 0 × 15
#> # ℹ 15 variables: origem <chr>, ano <int>, mes <int>, dia <int>, hora <int>,
#> # temperatura <dbl>, ponto_condensacao <dbl>, umidade <dbl>, …19.2.3 Chaves substitutas (Surrogate keys)
Até agora não falamos sobre a chave primária para voos. Não é muito importante aqui, porque não existem data frames que o utilizem como chave estrangeira, mas ainda é útil considerar porque é mais fácil trabalhar com observações se tivermos alguma maneira de descrevê-las para outras pessoas.
Após um pouco de reflexão e experimentação, determinamos que existem três variáveis que juntas identificam cada voo de forma única:
A ausência de linhas duplicadas torna automaticamente data_hora-companhia_aerea-voo uma chave primária? Certamente é um bom começo, mas não garante isso. Por exemplo, latitude e longitude são boas chaves primárias para aeroportos?
Identificar um aeroporto pela sua latitude e longitude é claramente uma má ideia e, em geral, não é possível saber apenas a partir dos dados se uma combinação de variáveis constitui ou não uma boa chave primária. Mas para voos, a combinação de data_hora,companhia_aerea e voo parece razoável porque seria muito confuso para uma companhia aérea e seus clientes se houvesse vários voos com o mesmo número de voo no ar ao mesmo tempo.
Dito isto, seria melhor introduzir uma chave substituta (surrogate key) numérica simples usando o número da linha:
voos2 <- voos |>
mutate(id = row_number(), .before = 1)
voos2
#> # A tibble: 336,776 × 20
#> id ano mes dia horario_saida saida_programada atraso_saida
#> <int> <int> <int> <int> <int> <int> <dbl>
#> 1 1 2013 1 1 517 515 2
#> 2 2 2013 1 1 533 529 4
#> 3 3 2013 1 1 542 540 2
#> 4 4 2013 1 1 544 545 -1
#> 5 5 2013 1 1 554 600 -6
#> 6 6 2013 1 1 554 558 -4
#> # ℹ 336,770 more rows
#> # ℹ 13 more variables: horario_chegada <int>, chegada_prevista <int>, …Chaves substitutas podem ser particularmente úteis na comunicação com outras pessoas: é muito mais fácil dizer a alguém para dar uma olhada no voo 2001 do que dizer para olhar o UA430, que partiu às 9h.
19.2.4 Exercícios
Esquecemos de desenhar a relação entre
climaeaeroportosna Figura 19.1. Qual é a relação e como ela deveria aparecer no diagrama?climacontém apenas informações para os três aeroportos de origem em Nova York (NYC). Se contivesse registros meteorológicos para todos os aeroportos dos EUA, que conexão adicional faria comvoos?As variáveis
ano,mês,dia,horaeorigemquase formam uma chave composta paraclima, mas há uma hora que tem observações duplicadas. Você consegue descobrir o que há de especial naquela hora?Sabemos que alguns dias do ano são especiais e menos pessoas do que o normal voam neles (por exemplo, véspera de Natal e dia de Natal). Como você poderia representar esses dados como um data frame? Qual seria a chave primária? Como ele se conectaria aos data frames existentes?
Desenhe um diagrama ilustrando as conexões entre os data frames
rebatedores,pessoasesalariosdo pacote dados. Desenhe outro diagrama que mostre o relacionamento entrepessoas,gerentes,premios_gerentes. Como você caracterizaria a relação entre os data framesrebatedores,arremessadoresejardineiros?
19.3 Uniões básicas
Agora que você entende como os data frames são conectados por meio de chaves (keys), podemos começar a usar uniões (joins) para entender melhor o conjunto de dados voos. O pacote dplyr fornece seis funções de união (join): left_join(), inner_join(), right_join(), full_join(), semi_join() e anti_join(). Todas elas têm a mesma interface: elas pegam dois data frames (x e y) e retornam um data frame. A ordem das linhas e colunas na saída é determinada principalmente por x.
Nesta seção, você aprenderá como usar uma união mutante (mutating join), left_join(), e duas uniões de filtragem (filtering join), semi_join() e anti_join(). Na próxima seção, você aprenderá exatamente como essas funções funcionam e também sobre as outras funções inner_join(), right_join() e full_join()
19.3.1 Uniões de mutação (Mutating joins)
Uma união de mutação (mutating join), permite combinar variáveis de dois data frames: primeiro ela combina as observações por suas chaves e depois copia as variáveis de um data frame para outro. Assim como mutate(), as funções de união (joins) adicionam variáveis à direita, portanto, se o seu conjunto de dados tiver muitas variáveis, você não verá as novas. Para esses exemplos, facilitaremos a visualização do que está acontecendo criando um conjunto de dados mais restrito com apenas seis variáveis2:
voos2 <- voos |>
select(ano, data_hora, origem, destino, codigo_cauda, companhia_aerea)
voos2
#> # A tibble: 336,776 × 6
#> ano data_hora origem destino codigo_cauda companhia_aerea
#> <int> <dttm> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA
#> # ℹ 336,770 more rowsExistem quatro tipos de uniões de mutação, mas há uma que você usará quase o tempo todo: left_join(). É especial porque a saída sempre terá as mesmas linhas de x, o data frame ao qual você está unindo3. O principal uso de left_join() é adicionar metadados adicionais. Por exemplo, podemos usar left_join() para adicionar o nome completo da companhia aérea aos dados voos2:
voos2 |>
left_join(companhias_aereas)
#> Joining with `by = join_by(companhia_aerea)`
#> # A tibble: 336,776 × 7
#> ano data_hora origem destino codigo_cauda companhia_aerea
#> <int> <dttm> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA
#> # ℹ 336,770 more rows
#> # ℹ 1 more variable: nome <chr>Ou poderíamos descobrir a temperatura e a velocidade do vento quando cada avião partiu:
voos2 |>
left_join(clima |> select(origem, data_hora, temperatura, velocidade_vento))
#> Joining with `by = join_by(data_hora, origem)`
#> # A tibble: 336,776 × 8
#> ano data_hora origem destino codigo_cauda companhia_aerea
#> <int> <dttm> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA
#> # ℹ 336,770 more rows
#> # ℹ 2 more variables: temperatura <dbl>, velocidade_vento <dbl>Ou que tamanho de avião estava voando:
voos2 |>
left_join(avioes |> select(codigo_cauda, tipo, motores, assentos))
#> Joining with `by = join_by(codigo_cauda)`
#> # A tibble: 336,776 × 9
#> ano data_hora origem destino codigo_cauda companhia_aerea
#> <int> <dttm> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA
#> # ℹ 336,770 more rows
#> # ℹ 3 more variables: tipo <chr>, motores <int>, assentos <int>Quando left_join() não consegue encontrar uma correspondência para uma linha em x, ele preenche as novas variáveis com valores ausentes (missing values). Por exemplo, não há informações sobre o avião com código de cauda N3ALAA, então o tipo, os motores e os assentos ficarão faltando:
voos2 |>
filter(codigo_cauda == "N3ALAA") |>
left_join(avioes |> select(codigo_cauda, tipo, motores, assentos))
#> Joining with `by = join_by(codigo_cauda)`
#> # A tibble: 63 × 9
#> ano data_hora origem destino codigo_cauda companhia_aerea tipo
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA <NA>
#> 2 2013 2013-01-02 18:00:00 LGA ORD N3ALAA AA <NA>
#> 3 2013 2013-01-03 06:00:00 LGA ORD N3ALAA AA <NA>
#> 4 2013 2013-01-07 19:00:00 LGA ORD N3ALAA AA <NA>
#> 5 2013 2013-01-08 17:00:00 JFK ORD N3ALAA AA <NA>
#> 6 2013 2013-01-16 06:00:00 LGA ORD N3ALAA AA <NA>
#> # ℹ 57 more rows
#> # ℹ 2 more variables: motores <int>, assentos <int>Voltaremos a esse problema algumas vezes no restante do capítulo.
19.3.2 Especificando chaves das uniões (Join keys)
Por padrão, left_join() usará todas as variáveis que aparecem em ambos os data frames como a chave de união (join key), a chamada união natural (natural join). Esta é uma heurística útil, mas nem sempre funciona. Por exemplo, o que acontece se tentarmos unir voos2 com o conjunto de dados completo avioes
voos2 |>
left_join(avioes)
#> Joining with `by = join_by(ano, codigo_cauda)`
#> # A tibble: 336,776 × 13
#> ano data_hora origem destino codigo_cauda companhia_aerea tipo
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA <NA>
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA <NA>
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA <NA>
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 <NA>
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL <NA>
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA <NA>
#> # ℹ 336,770 more rows
#> # ℹ 6 more variables: fabricante <chr>, modelo <chr>, motores <int>, …Obtemos muitas correspondências perdidas porque nossa união está tentando usar codigo_cauda e ano como chave composta. Tanto voos quanto avioes têm uma coluna ano, mas significam coisas diferentes: voos$ano é o ano em que o voo ocorreu e avioes$ano é o ano em que o avião foi construído. Queremos unir usando apenas codigo_cauda, então precisamos fornecer uma especificação explícita com join_by():
voos2 |>
left_join(avioes, join_by(codigo_cauda))
#> # A tibble: 336,776 × 14
#> ano.x data_hora origem destino codigo_cauda companhia_aerea ano.y
#> <int> <dttm> <chr> <chr> <chr> <chr> <int>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA 1999
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA 1998
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA 1990
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 2012
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL 1991
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA 2012
#> # ℹ 336,770 more rows
#> # ℹ 7 more variables: tipo <chr>, fabricante <chr>, modelo <chr>, …Observe que as variáveis ano são diferenciadas na saída com um sufixo (ano.x e ano.y), que informa se a variável veio do argumento x ou y. Você pode substituir os sufixos padrão pelo argumento suffix.
join_by(codigo_cauda) é a abreviação de join_by(codigo_cauda == codigo_cauda). É importante conhecer essa forma mais completa por dois motivos. Em primeiro lugar, descreve a relação entre as duas tabelas: as chaves devem ser iguais. É por isso que esse tipo de união costuma ser chamado de união equivalente (equi join). Você aprenderá sobre uniões não equivalentes (non-equi join) na Seção 19.5.
Em segundo lugar, é como você especifica diferentes chaves de união (join keys) em cada tabela. Por exemplo, existem duas maneiras de unir as tabelas voos2 e aeroportos: por destino ou origem:
voos2 |>
left_join(aeroportos, join_by(destino == codigo_aeroporto))
#> # A tibble: 336,776 × 13
#> ano data_hora origem destino codigo_cauda companhia_aerea
#> <int> <dttm> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA
#> # ℹ 336,770 more rows
#> # ℹ 7 more variables: nome <chr>, latitude <dbl>, longitude <dbl>, …
voos2 |>
left_join(aeroportos, join_by(origem == codigo_aeroporto))
#> # A tibble: 336,776 × 13
#> ano data_hora origem destino codigo_cauda companhia_aerea
#> <int> <dttm> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA
#> # ℹ 336,770 more rows
#> # ℹ 7 more variables: nome <chr>, latitude <dbl>, longitude <dbl>, …Em códigos mais antigos, você pode ver uma maneira diferente de especificar as chaves de união, usando um vetor de caracteres:
-
by = "x"corresponde ajoin_by(x). -
by = c("a" = "x")corresponde ajoin_by(a == x).
Agora que isto existe, preferimos join_by() pois fornece uma especificação mais clara e flexível.
inner_join(), right_join(), full_join() têm a mesma interface que left_join(). A diferença é quais linhas as funções mantêm: a left join mantém todas as linhas em x, a right join mantém todas as linhas em y, a full join mantém todas as linhas em x ou y, e a inner join mantém apenas as linhas que ocorrem em x e y. Voltaremos a isso com mais detalhes posteriormente.
19.3.3 Uniões de filtragem (Filtering joins)
Como você pode imaginar, a ação principal de uma união de filtragem (filtering joins) é filtrar as linhas. Existem dois tipos: semi-união (semi-join) e anti-união (anti-join). Semi-união (semi-join) mantêm todas as linhas em x que correspondem a y. Por exemplo, poderíamos usar um semi-join para filtrar o conjunto de dados aeroportos para mostrar apenas os aeroportos de origem:
aeroportos |>
semi_join(voos2, join_by(codigo_aeroporto == origem))
#> # A tibble: 3 × 8
#> codigo_aeroporto nome latitude longitude altura fuso_horario
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 EWR Newark Liberty Intl 40.7 -74.2 18 -5
#> 2 JFK John F Kennedy Intl 40.6 -73.8 13 -5
#> 3 LGA La Guardia 40.8 -73.9 22 -5
#> # ℹ 2 more variables: horario_verao <chr>, fuso_horario_iana <chr>Ou apenas de destino:
aeroportos |>
semi_join(voos2, join_by(codigo_aeroporto == destino))
#> # A tibble: 101 × 8
#> codigo_aeroporto nome latitude longitude altura fuso_horario
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 ABQ Albuquerque Intern… 35.0 -107. 5355 -7
#> 2 ACK Nantucket Mem 41.3 -70.1 48 -5
#> 3 ALB Albany Intl 42.7 -73.8 285 -5
#> 4 ANC Ted Stevens Anchor… 61.2 -150. 152 -9
#> 5 ATL Hartsfield Jackson… 33.6 -84.4 1026 -5
#> 6 AUS Austin Bergstrom I… 30.2 -97.7 542 -6
#> # ℹ 95 more rows
#> # ℹ 2 more variables: horario_verao <chr>, fuso_horario_iana <chr>Anti-união (anti-join) é o oposto: ela retorno todas as linha em x que não possuem correspondência em y. Eles são úteis para encontrar valores ausentes (missing values) que estão implícitos nos dados, o tópico tratado no Seção 18.3. Valores implicitamente ausentes não aparecem como NAs, mas existem apenas como uma ausência. Por exemplo, podemos encontrar linhas que estão faltando em aeroportos procurando voos que não tenham um aeroporto de destino correspondente.
Ou podemos encontrar cada valor em codigo_cauda que estiverem ausentes de avioes:
19.3.4 Exercícios
Encontre as 48 horas (ao longo do ano) que apresentam os piores atrasos. Faça referência cruzada com os dados
clima. Você consegue ver algum padrão?-
Imagine que você encontrou os 10 destinos mais populares usando este código:
Como você pode encontrar todos os voos para esses destinos?
Cada voo de saída possui dados de clima correspondentes para aquela hora??
O que os código de cauda que não possuem um registro correspondente em
avioestêm em comum? (Dica: uma variável explica cerca de 90% dos problemas.)Adicione uma coluna a
avioesque liste todas ascompanhia_aereasque voaram naquele avião. Você poderia esperar que exista uma relação implícita entre avião e companhia aérea, porque cada avião é pilotado por uma única companhia aérea. Confirme ou rejeite esta hipótese usando as ferramentas que você aprendeu nos capítulos anteriores.Adicione a latitude e a longitude do aeroporto de origem e de destino a
voos. É mais fácil renomear as colunas antes ou depois da união (join)?-
Calcule o atraso médio por destino e, em seguida, una-o ao data frame
aeroportospara poder mostrar a distribuição espacial dos atrasos. Esta é uma maneira fácil de desenhar um mapa dos Estados Unidos:aeroportos |> semi_join(voos, join_by(codigo_aeroporto == destino)) |> ggplot(aes(x = longitude, y = latitude)) + borders("state") + geom_point() + coord_quickmap()Você pode querer usar o
tamanhoou acordos pontos para exibir o atraso médio de cada aeroporto. O que aconteceu em 13 de junho de 2013? Desenhe um mapa dos atrasos e use o Google para fazer referência cruzada com o clima.
19.4 Como as uniões (joins) funcionam?
Agora que você já usou uniões (joins) algumas vezes, é hora de aprender mais sobre como eles funcionam, focando em como cada linha em x corresponde às linhas em y. Começaremos apresentando uma representação visual de uniões (joins), usando os tibbles simples definidos abaixo e mostrados na Figura 19.2. Nestes exemplos usaremos uma única chave chamada chave e uma única coluna de valor (val_x e val_y), mas todas as ideias se generalizam para múltiplas chaves e múltiplos valores.
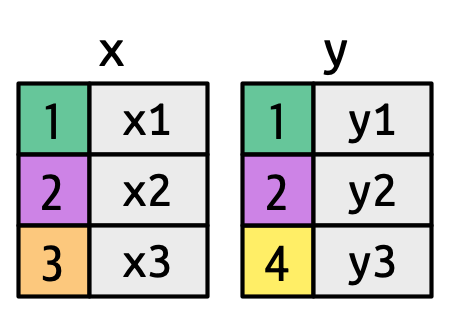
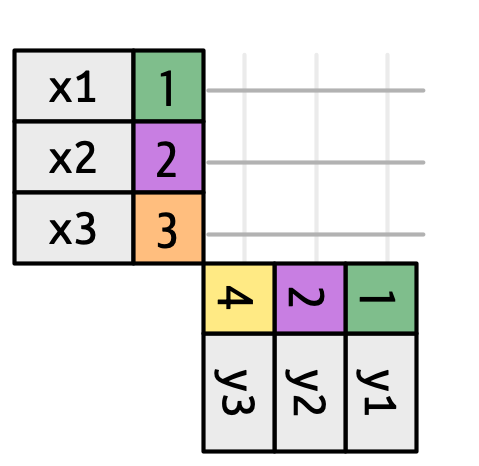
A Figura 19.3 apresenta a base para nossa representação visual Ele mostra todas as correspondências potenciais entre x e y como a interseção entre as linhas desenhadas de cada linha de x e cada linha de y.. As linhas e colunas na saída são determinadas principalmente por x, então a tabela x é horizontal e se alinha com a saída.
Para descrever um tipo específico de união, indicamos correspondências com pontos. As correspondências determinam as linhas na saída, um novo data frame que contém a chave (key), os valores (values) x e os valores y. Por exemplo, a Figura 19.4 mostra uma união interna (inner join), onde as linhas são retidas se e somente se as chaves forem iguais.
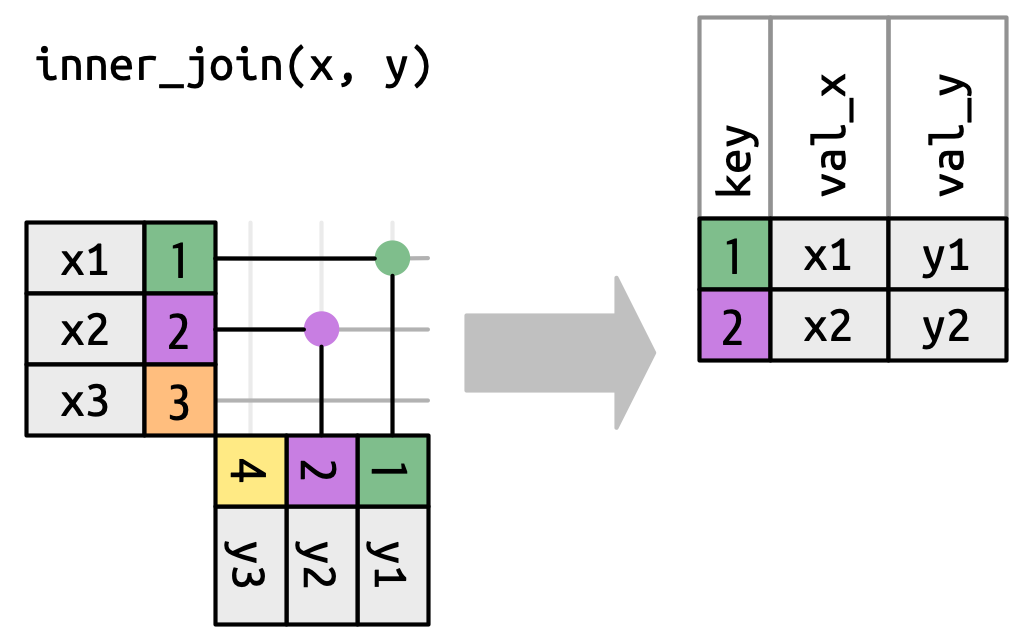
x com a linha em y que tem o mesmo valor de chave. Cada correspondência se torna uma linha na saída.
Podemos aplicar os mesmos princípios para explicar as uniões externas (outer joins), que mantêm observações que aparecem em pelo menos um dos data frames. Essas uniões funcionam adicionando uma observação “virtual” a cada data frame. Esta observação tem uma chave que corresponde se nenhuma outra chave corresponder e valores preenchidos com NA. Existem três tipos de uniões externas:
-
Uma união esquerda (left join) mantém todas as observações em
x, Figura 19.5. Cada linha dexé preservada na saída porque pode voltar a corresponder a uma linha deNAs emy.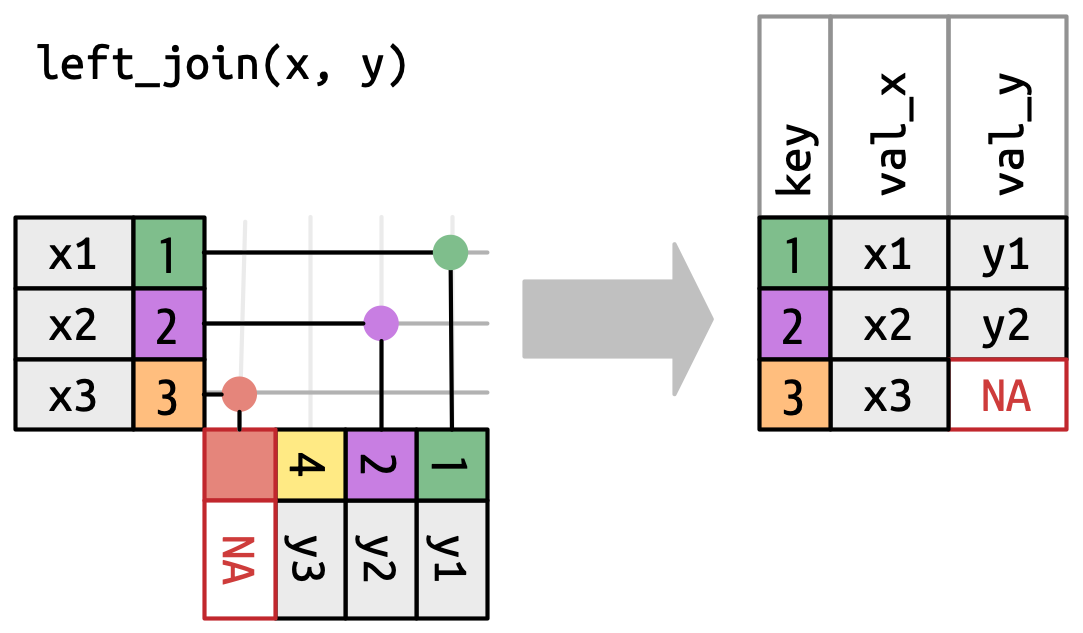
Figura 19.5: Uma representação visual da união esquerda onde cada linha em xaparece na saída. -
Uma união direita (right join) mantém todas as observações em
y, Figura 19.6. Cada linha deyé preservada na saída porque pode voltar a corresponder a uma linha deNAs emx. A saída ainda corresponde axtanto quanto possível; quaisquer linhas extras deysão adicionadas ao final.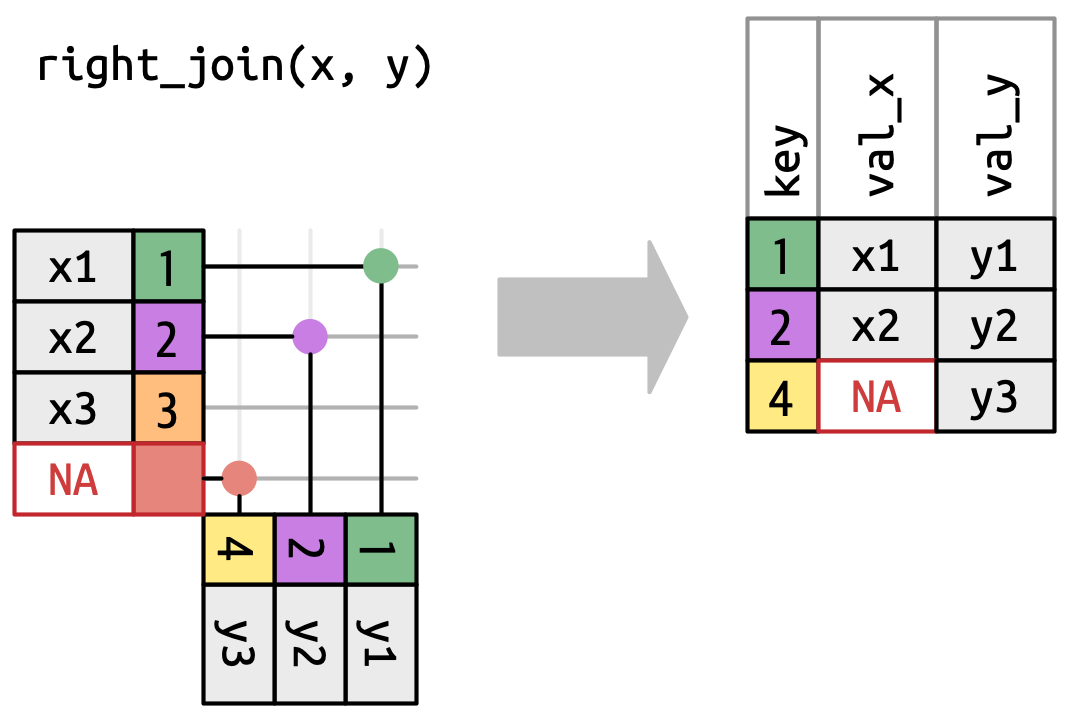
Figura 19.6: Uma representação visual da união direita onde cada linha de yaparece na saída. -
Uma união completa (full join) mantém todas as observações que aparecem em
xouy, Figura 19.7. Cada linha dexeyé incluída na saída porque ambosxeytêm uma linha alternativa deNAs. Novamente, a saída começa com todas as linhas dex, seguidas pelas linhasyrestantes sem correspondência.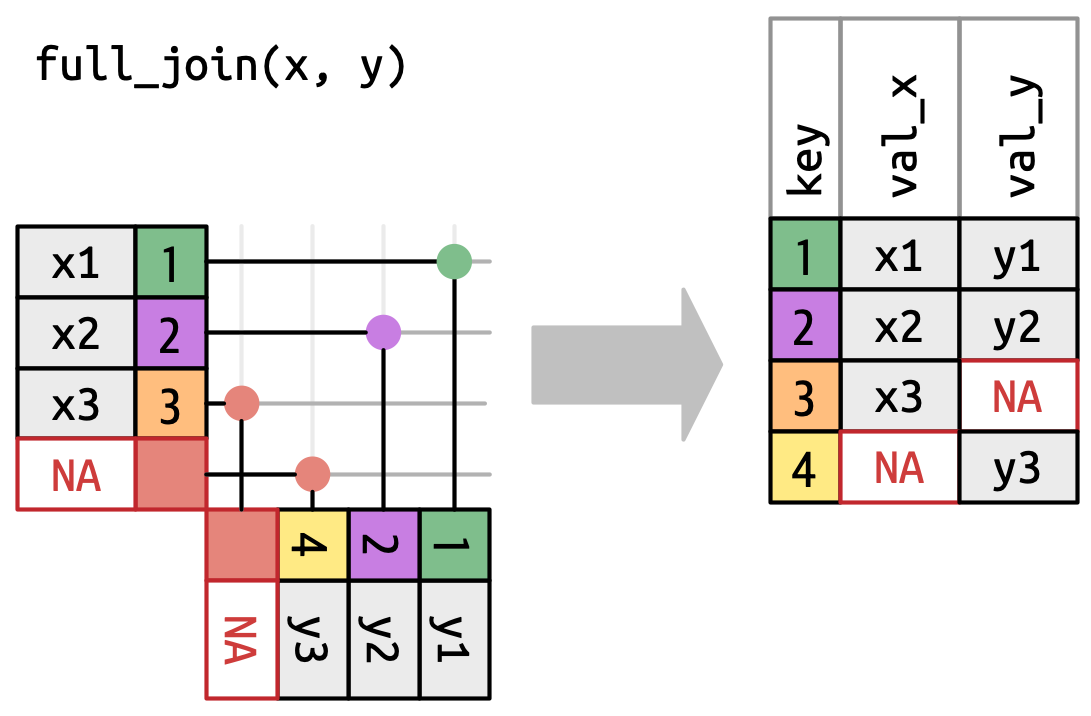
Figura 19.7: Uma representação visual da união completa (full join) onde cada linha em xeyaparece na saída.
Outra maneira de mostrar como os tipos de uniões externas (outer joins) diferem é com um diagrama de Venn, como na Figura 19.8. No entanto, esta não é uma boa representação porque, embora possa refrescar sua memória sobre quais linhas são preservadas, ela não ilustra o que está acontecendo com as colunas.
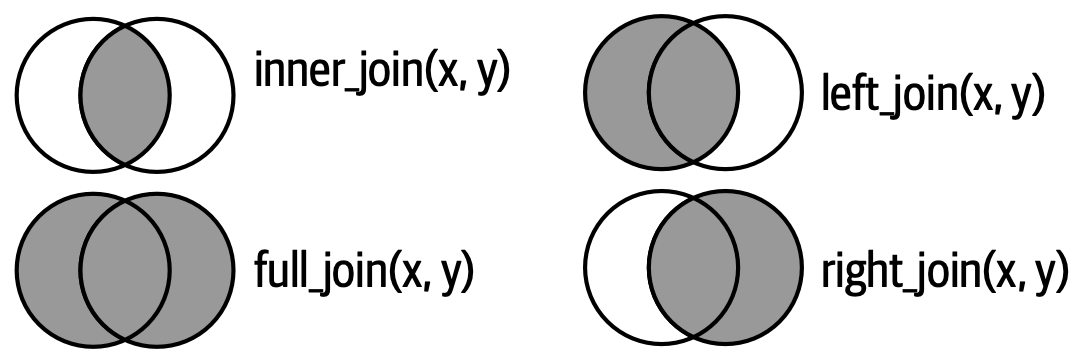
As uniões mostradas até aqui são chamadas uniões equivalentes (equi joins), onde as linhas correspondem se as chaves forem iguais. Uniões equivalentes (equi joins) são o tipo mais comum de união, então normalmente omitiremos o prefixo equi e apenas diremos “união interna” (inner join) em vez de “união interna equivalente” (equi inner join). Voltaremos às uniões não-equivalentes (non-equi joins) no Seção 19.5.
19.4.1 Correspondências de linhas
Até agora, exploramos o que acontece se uma linha em x corresponder a zero ou a uma linha em y. O que acontece se corresponder a mais de uma linha? Para entender o que está acontecendo, vamos primeiro restringir nosso foco à função inner_join() e então fazer um desenho, Figura 19.9.
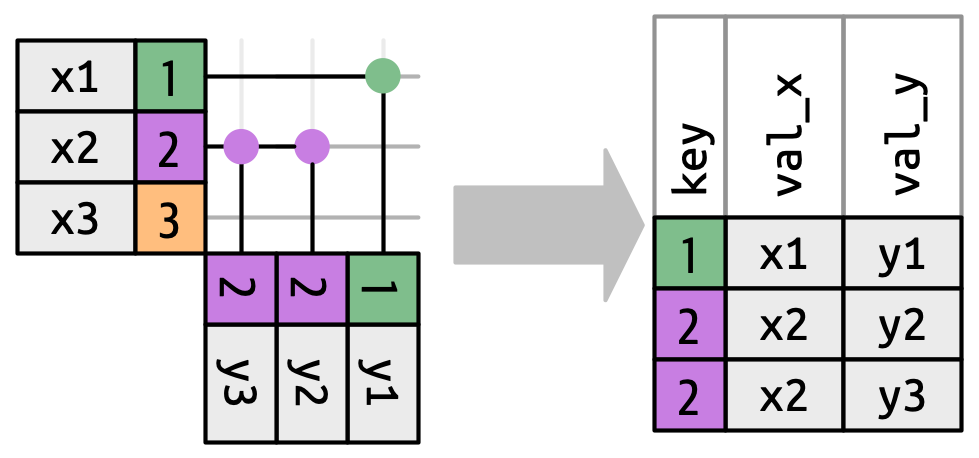
x pode corresponder. x1 corresponde uma linha em y, x2 corresponde a duas linhas em y, x3 corresponde zero linhas em y. Observe que embora existam três linhas em x e três linhas na saída, não há um direta correspondência entre as linhas.
Existem três resultados possíveis para uma linha em x::
- Se não corresponder a nada, é descartado.
- Se corresponder a 1 linha em
y, é preservado. - Se corresponder a mais de 1 linha em
y, será duplicado uma vez para cada correspondência.
Em princípio, isso significa que não há correspondência garantida entre as linhas na saída e as linhas em x, mas na prática, isso raramente causa problemas. Existe, no entanto, um caso particularmente perigoso que pode causar uma explosão combinatória de linhas. Imagine fazer a união (join) das duas tabelas a seguir:
Enquanto a primeira linha em df1 corresponde apenas a uma linha em df2, a segunda e a terceira linhas correspondem a duas linhas. Isso às vezes é chamado de relacionamento muitos para muitos (many-to-many relationship) e fará com que o dplyr emita um aviso:
df1 |>
inner_join(df2, join_by(chave))
#> Warning in inner_join(df1, df2, join_by(chave)): Detected an unexpected many-to-many relationship between `x` and `y`.
#> ℹ Row 2 of `x` matches multiple rows in `y`.
#> ℹ Row 2 of `y` matches multiple rows in `x`.
#> ℹ If a many-to-many relationship is expected, set `relationship =
#> "many-to-many"` to silence this warning.
#> # A tibble: 5 × 3
#> chave val_x val_y
#> <dbl> <chr> <chr>
#> 1 1 x1 y1
#> 2 2 x2 y2
#> 3 2 x2 y3
#> 4 2 x3 y2
#> 5 2 x3 y3Se você estiver fazendo isso deliberadamente, você pode definir relationship = "many-to-many", como o aviso sugere.
19.4.2 Uniões de filtragem (Filtering joins)
O número de correspondências também determina o comportamento das uniões de filtragem (filtering joins). A semi-união (semi-join) mantém linhas em x que possuem uma ou mais correspondências em y, como em Figura 19.10. A anti-união **anti-join) mantém linhas em x que correspondem a zero linhas em y, como na @ fig-join-anti. Em ambos os casos, apenas a existência de uma correspondência é importante; não importa quantas vezes corresponda. Isso significa que as uniões de filtragem (filtering joins) nunca duplicam linhas como as uniões de mutação (mutating joins*) fazem.
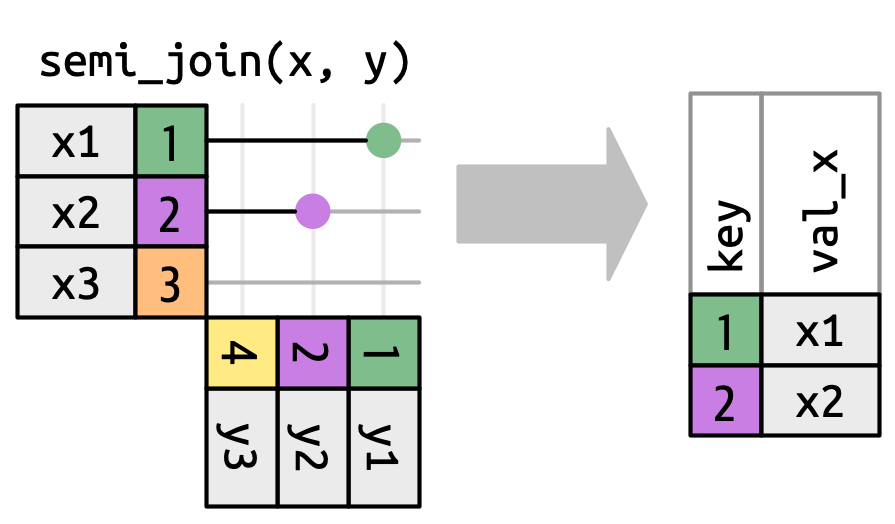
valores emy` não afetam a saída.
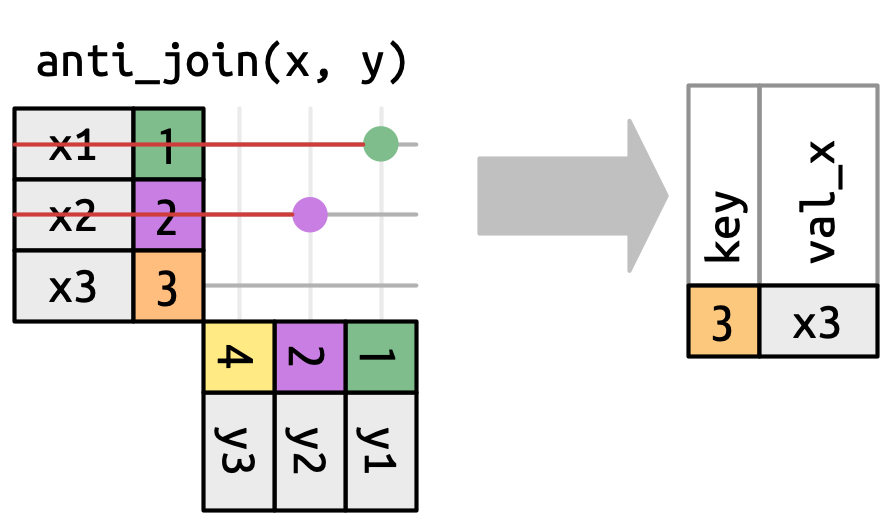
x que têm uma correspondência em y.
19.5 Uniões não-equivalentes
Até agora você só viu uniões equivalentes (equi joins), uniões onde as linhas correspondem se a chave x for igual à chave y. Agora vamos relaxar essa restrição e discutir outras maneiras de determinar se um par de linhas se corresponde.
Mas antes de podermos fazer isso, precisamos rever uma simplificação que fizemos acima. Nas uniões equivalentes (equi joins), as chaves x e y são sempre iguais, então só precisamos mostrar uma na saída. Podemos solicitar que dplyr mantenha ambas as chaves com keep = TRUE, o que leva ao código abaixo e ao inner_join() redesenhado na @ fig-inner-both.
x |> inner_join(y, join_by(chave == chave), keep = TRUE)
#> # A tibble: 2 × 4
#> chave.x val_x chave.y val_y
#> <dbl> <chr> <dbl> <chr>
#> 1 1 x1 1 y1
#> 2 2 x2 2 y2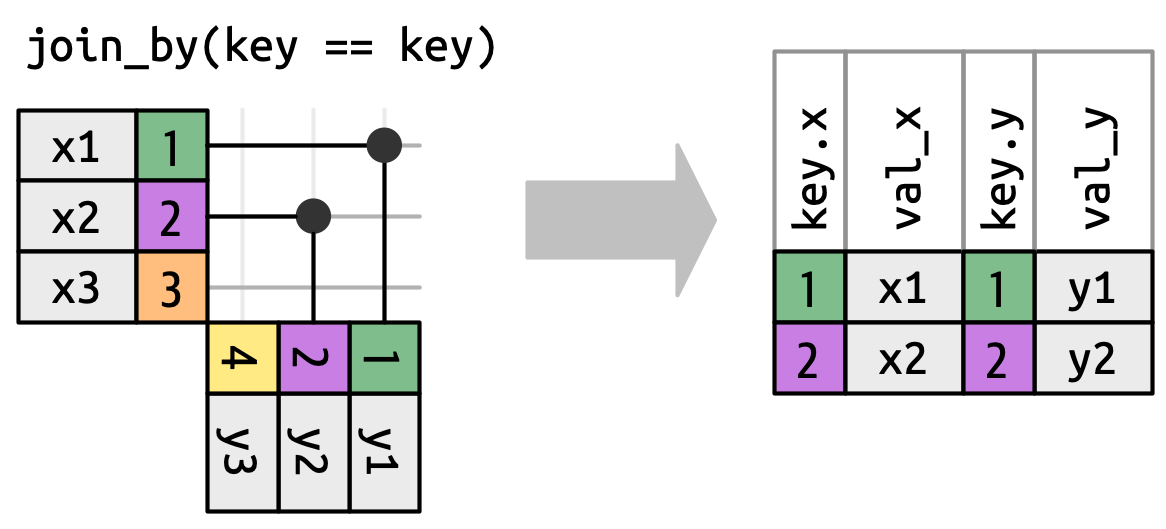
x quanto a chave y na saída.
Quando nos afastamos das uniões equivalentes (equi joins), sempre mostraremos as chaves (keys), porque os valores das chaves geralmente serão diferentes. Por exemplo, em vez de combinar apenas quando x$chave e y$chave forem iguais, poderíamos combinar sempre que x$chave for maior ou igual a y$chave, levando a @fig -junte-gte. As funções de união do pacote dplyr entendem essa distinção entre uniões equivalentes (equi joins) e uniões não-equivalentes (non-equi joins), portanto sempre mostrarão ambas as chaves quando você realizar uma união não-equivalente.
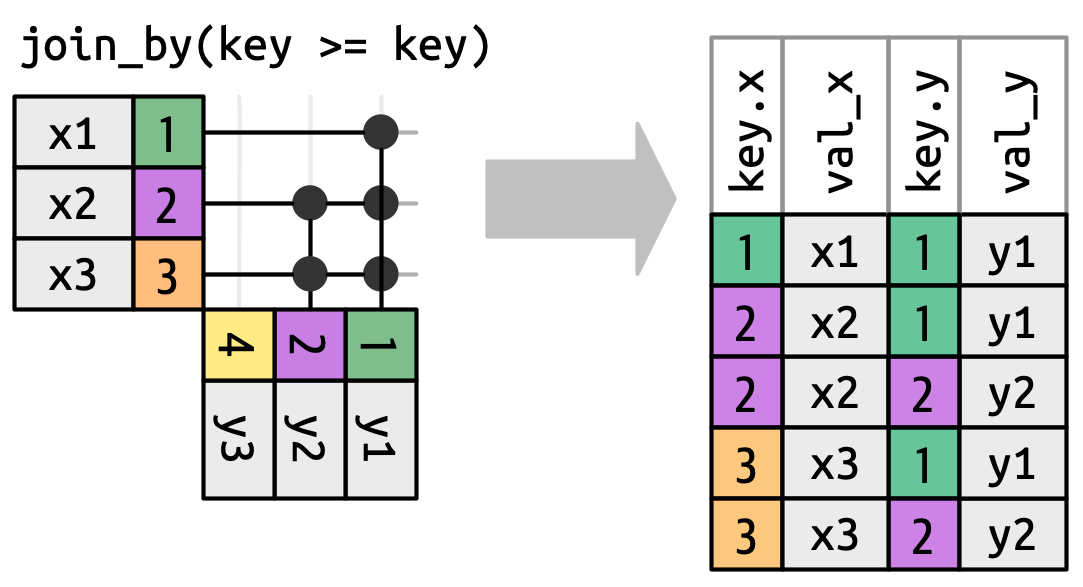
x deve ser maior ou igual a chave em y. Muitas linhas geram múltiplas correspondências.
União não-equivalente (non-equi join) não é um termo particularmente útil porque apenas informa o que a união não é, e não o que é. O dplyr ajuda a identificar quatro tipos particularmente úteis de uniões não-equivalentes:
- Uniões cruzadas (cross joins) correspondem a cada par de linhas.
-
Uniões de desigualdades (inequality joins) usam
<,<=,>e>=em vez de==. - Uniões deslizantes (rolling joins) são semelhantes às uniões de desigualdade, mas apenas encontram a correspondência mais próxima.
- Uniões de sobreposições (overlap joins) são um tipo especial de união de desigualdade projetada para trabalhar com intervalos.
Cada um deles é descrito em maiores detalhes nas seções a seguir.
19.5.1 Uniões cruzadas (Cross joins)
Uma união cruzada (cross join) corresponde a tudo, como na Figura 19.14, gerando o produto cartesiano de linhas. Isso significa que a saída terá linhas nrow(x) * nrow(y).
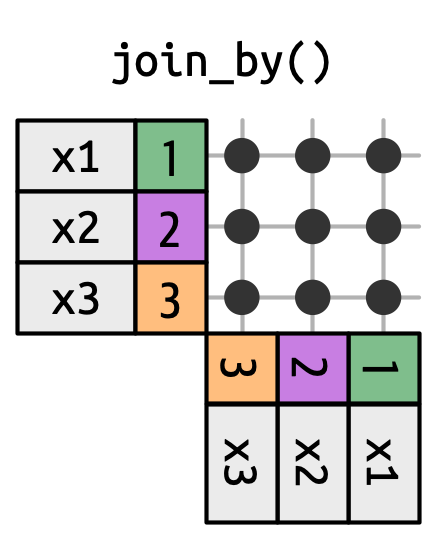
x com cada linha em y.
As uniões cruzadas são úteis ao gerar permutações. Por exemplo, o código abaixo gera todos os pares possíveis de nomes. Como estamos unindo df a ele mesmo, isso às vezes é chamado de auto-união (self-join). As uniões cruzadas usam uma função de união diferente porque não há distinção entre interno/esquerdo/direito/completo quando você corresponde todas as linhas.
df <- tibble(name = c("João", "Maria", "José", "Ana"))
df |> cross_join(df)
#> # A tibble: 16 × 2
#> name.x name.y
#> <chr> <chr>
#> 1 João João
#> 2 João Maria
#> 3 João José
#> 4 João Ana
#> 5 Maria João
#> 6 Maria Maria
#> # ℹ 10 more rows19.5.2 Uniões de desigualdades (Inequality joins)
Uniões de desigualdade (inequality joins) usam <, <=, >= ou > para restringir o conjunto de correspondências possíveis, como em Figura 19.13 e Figura 19.15.
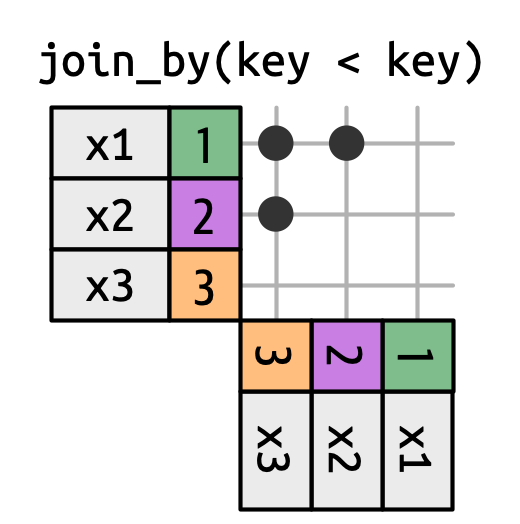
x é unido a y nas linhas onde a chave de x é menor que a chave de y. Isso retorna uma forma triangular no canto superior esquerdo.
As uniões de desigualdade são extremamente gerais, tão gerais que é difícil encontrar casos relevantes de uso específico. Uma pequena técnica útil é usá-los para restringir a união cruzada de modo que, em vez de gerar todas as permutações, geremos todas as combinações:
df <- tibble(id = 1:4, name = c("João", "Maria", "José", "Ana"))
df |> inner_join(df, join_by(id < id))
#> # A tibble: 6 × 4
#> id.x name.x id.y name.y
#> <int> <chr> <int> <chr>
#> 1 1 João 2 Maria
#> 2 1 João 3 José
#> 3 1 João 4 Ana
#> 4 2 Maria 3 José
#> 5 2 Maria 4 Ana
#> 6 3 José 4 Ana19.5.3 Uniões deslizantes (Rolling joins)
Uniões deslizantes (rolling joins) são um tipo especial de união de desigualdade em que ao invés de obter todas as linhas que satisfaçam a desigualdade, você obtém apenas a linha mais próxima, como na @ fig-join-closest. Você pode transformar qualquer união de desigualdade em uma união deslizante adicionando a função closest(). Por exemplo, join_by(closest(x <= y)) corresponde ao menor y que é maior ou igual a x, e join_by(closest(x > y)) corresponde ao maior y que é menor que x
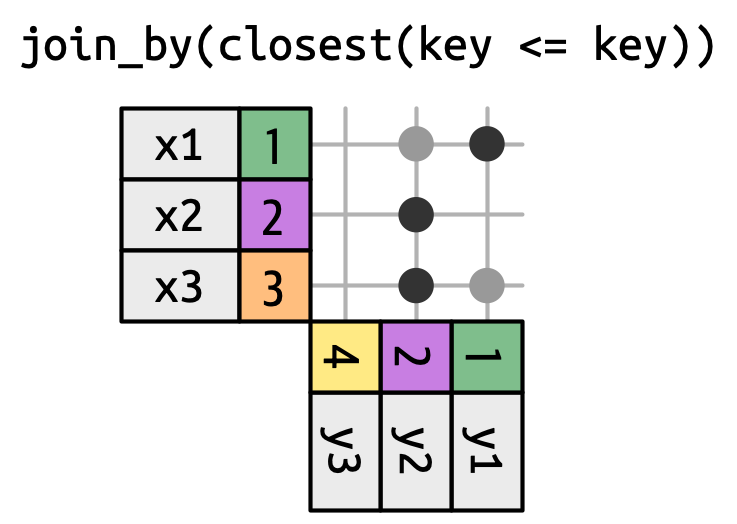
As uniões deslizantes (rolling joins) são particularmente úteis quando você tem duas tabelas de datas que não estão perfeitamente alinhadas e deseja encontrar (por exemplo) a data mais próxima na tabela 1 que vem antes (ou depois) de alguma data na tabela 2.
Por exemplo, imagine que você é responsável pela comissão de planejamento de festas do seu escritório. Sua empresa é bastante econômica, então, em vez de dar festas individuais, você só dá uma vez a cada trimestre. As regras para determinar quando uma festa será realizada são um pouco complexas: as festas são sempre na segunda-feira, você pula a primeira semana de janeiro porque muita gente está de férias, e a primeira segunda-feira do terceiro trimestre de 2022 é 4 de julho (feirado), então isso tem que ser adiado por uma semana. Isso leva aos seguintes dias de festa:
Agora imagine que você tem uma tabela de aniversários de funcionários:
set.seed(123)
funcionarios <- tibble(
nome = sample(dados::bebes$nome, 100),
aniversario = ymd("2022-01-01") + (sample(365, 100, replace = TRUE) - 1)
)
funcionarios
#> # A tibble: 100 × 2
#> nome aniversario
#> <chr> <date>
#> 1 Kemba 2022-01-22
#> 2 Orean 2022-06-26
#> 3 Kirstyn 2022-02-11
#> 4 Amparo 2022-11-11
#> 5 Belen 2022-03-25
#> 6 Rayshaun 2022-01-11
#> # ℹ 94 more rowsE para cada funcionário queremos encontrar a data da primeira festa que ocorre depois (ou no dia) do seu aniversário. Podemos expressar isso com uma união deslizante:
funcionarios |>
left_join(festas, join_by(closest(aniversario >= festa)))
#> # A tibble: 100 × 4
#> nome aniversario trimetre festa
#> <chr> <date> <int> <date>
#> 1 Kemba 2022-01-22 1 2022-01-10
#> 2 Orean 2022-06-26 2 2022-04-04
#> 3 Kirstyn 2022-02-11 1 2022-01-10
#> 4 Amparo 2022-11-11 4 2022-10-03
#> 5 Belen 2022-03-25 1 2022-01-10
#> 6 Rayshaun 2022-01-11 1 2022-01-10
#> # ℹ 94 more rowsHá, no entanto, um problema com esta abordagem: quem faz aniversário antes de 10 de janeiro não ganha festa:
Para resolver este problema, precisaremos abordar o problema de uma maneira diferente, com uniões de sobreposições (overlap joins).
19.5.4 Uniões de sobreposições (Overlap joins)
Uniões de sobreposições (overlap joins) fornecem três funções de ajuda que usam uniões de desigualdade para facilitar o trabalho com intervalos:
-
between(x, y_inferior, y_superior)é uma abreviação parax >= y_inferior, x <= y_superior. -
within(x_inferior, x_superior, y_inferior, y_superior)é uma abreviação parax_inferior >= y_inferior, x_superior <= y_superior. -
overlaps(x_inferior, x_superior, y_inferior, y_superior)é uma abreviação parax_inferior <= y_superior, x_superior >= y_inferior.
Vamos continuar o exemplo do aniversário para ver como você pode usá-los. Há um problema com a estratégia que usamos acima: não há festa antes dos aniversários de 1º a 9 de janeiro. Portanto, talvez seja melhor ser explícito sobre os intervalos de datas que cada festa abrange e apresentar um caso especial para os aniversários antecipados:
festas <- tibble(
trimestre = 1:4,
festa = ymd(c("2022-01-10", "2022-04-04", "2022-07-11", "2022-10-03")),
inicio = ymd(c("2022-01-01", "2022-04-04", "2022-07-11", "2022-10-03")),
fim = ymd(c("2022-04-03", "2022-07-11", "2022-10-02", "2022-12-31"))
)
festas
#> # A tibble: 4 × 4
#> trimestre festa inicio fim
#> <int> <date> <date> <date>
#> 1 1 2022-01-10 2022-01-01 2022-04-03
#> 2 2 2022-04-04 2022-04-04 2022-07-11
#> 3 3 2022-07-11 2022-07-11 2022-10-02
#> 4 4 2022-10-03 2022-10-03 2022-12-31O Hadley é terrivelmente ruim na entrada de dados, então ele também queria verificar se os períodos das festas não se sobrepunham. Uma maneira de fazer isso é usar uma auto-união (self-join) para verificar se algum intervalo inicio-fim se sobrepõe a outro:
festas |>
inner_join(festas, join_by(overlaps(inicio, fim, inicio, fim), trimestre < trimestre)) |>
select(inicio.x, fim.x, inicio.y, fim.y)
#> # A tibble: 1 × 4
#> inicio.x fim.x inicio.y fim.y
#> <date> <date> <date> <date>
#> 1 2022-04-04 2022-07-11 2022-07-11 2022-10-02Ops, há uma sobreposição, então vamos corrigir este problema e continuar:
Agora podemos combinar cada funcionário com seu grupo. Este é um bom lugar para usar o argumento unmatched = "error", porque queremos descobrir rapidamente se algum funcionário não foi designado para um grupo.
funcionarios |>
inner_join(festas, join_by(between(aniversario, inicio, fim)), unmatched = "error")
#> # A tibble: 100 × 6
#> nome aniversario trimestre festa inicio fim
#> <chr> <date> <int> <date> <date> <date>
#> 1 Kemba 2022-01-22 1 2022-01-10 2022-01-01 2022-04-03
#> 2 Orean 2022-06-26 2 2022-04-04 2022-04-04 2022-07-10
#> 3 Kirstyn 2022-02-11 1 2022-01-10 2022-01-01 2022-04-03
#> 4 Amparo 2022-11-11 4 2022-10-03 2022-10-03 2022-12-31
#> 5 Belen 2022-03-25 1 2022-01-10 2022-01-01 2022-04-03
#> 6 Rayshaun 2022-01-11 1 2022-01-10 2022-01-01 2022-04-03
#> # ℹ 94 more rows19.5.5 Exercícios
-
Você pode explicar o que está acontecendo com as chaves (keys) nesta união equivalente (equi join)? Por que elas são diferentes?
x |> full_join(y, join_by(chave == chave)) #> # A tibble: 4 × 3 #> chave val_x val_y #> <dbl> <chr> <chr> #> 1 1 x1 y1 #> 2 2 x2 y2 #> 3 3 x3 <NA> #> 4 4 <NA> y3 x |> full_join(y, join_by(chave == chave), keep = TRUE) #> # A tibble: 4 × 4 #> chave.x val_x chave.y val_y #> <dbl> <chr> <dbl> <chr> #> 1 1 x1 1 y1 #> 2 2 x2 2 y2 #> 3 3 x3 NA <NA> #> 4 NA <NA> 4 y3 Ao descobrir se algum período de festa se sobrepôs a outro período de festa, usamos
trimestre < trimestreemjoin_by()? Por que? O que acontece se você remover essa desigualdade?
19.6 Resumo
Neste capítulo, você aprendeu como usar uniões de mutações (mutating joins) e filtragem (filtering joins) para combinar dados de dois data frames. Ao longo do caminho você aprendeu como identificar chaves (keys) e a diferença entre chaves primárias (primary keys) e estrangeiras (foreign keys). Você também entende como funcionam as uniões e como descobrir quantas linhas a saída terá. Finalmente, você teve uma ideia do poder das uniões não-equivalentes (non-equi joins) e viu alguns casos interessantes de seu uso.
Este capítulo conclui a parte “Transformar” do livro, onde o foco estava nas ferramentas que você poderia usar com colunas e tabelas individuais. Você aprendeu sobre o pacote dyplr e suas funções base para trabalhar com vetores lógicos, números e tabelas completas, funções do pacote stringr para trabalhar com strings, funções do pacote lubridate para trabalhar com datas e horários e funções do pacote forcats para trabalhar com fatores.
Na próxima parte do livro, você aprenderá mais sobre como colocar vários tipos de dados em R de uma forma organizada (tidy).