✅ Introdução
Ciência de dados é uma área emocionante que permite que você transforme dados brutos em compreensão, insights e conhecimento. O objetivo do livro “R para Ciência de Dados” é ajudar você a aprender as ferramentas mais importantes em R que permitirão que você realize ciência de dados de forma eficiente e reprodutível, e se divirta ao longo do caminho 😃. Após a leitura deste livro, você terá as ferramentas necessárias para enfrentar uma ampla variedade de desafios de ciência de dados usando as melhores partes do R.
O que você aprenderá
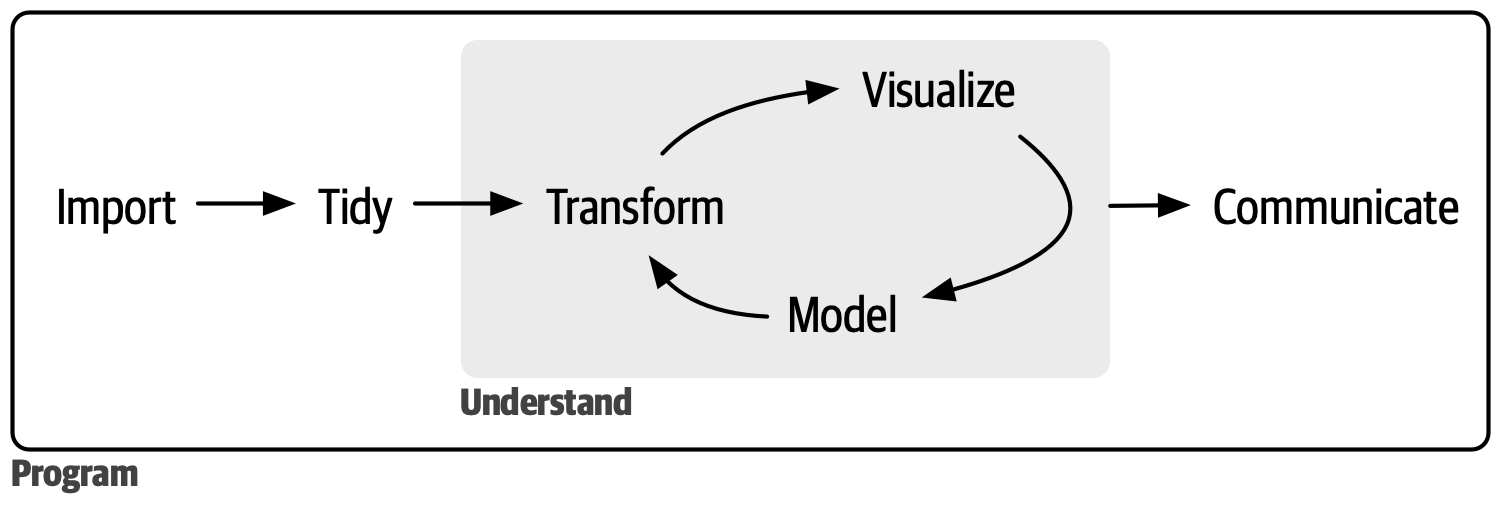
A ciência de dados é um campo vasto, e não é possível dominá-la lendo apenas um único livro. Este livro tem como objetivo fornecer a você uma base sólida nas ferramentas mais importantes e conhecimento suficiente para encontrar os recursos necessários para aprender mais quando for preciso. Nosso modelo das etapas de um projeto típico de ciência de dados se parece com Figura Em nosso modelo do processo de ciência de dados, você começa com a importação e organização dos dados. Em seguida, você entende seus dados por meio de um ciclo iterativo de transformação, visualização e modelagem. Você finaliza o ciclo comunicando seus resultados para outras pessoas..
Primeiro, você deve importar seus dados para o R. Isso geralmente significa que você pega dados armazenados em um arquivo, um banco de dados ou uma API (interface de programação de aplicação, ou Application Programming Interface em inglês) da web e importa em uma tabela (data frame) no R. Se você não conseguir importar seus dados para o R, não poderá fazer ciência de dados com eles!
Depois de importar seus dados, é uma boa ideia organizá-los .
Organizar seus dados significa armazená-los em uma forma consistente que corresponda à semântica do conjunto de dados com a forma como ele é armazenado. Em resumo, quando seus dados estão organizados no formato tidy1, cada coluna é uma variável e cada linha é uma observação.
Dados no formato tidy (tidy data) são importantes porque a estrutura consistente permite que você concentre seus esforços em responder perguntas sobre os dados, em vez de lutar para colocar os dados na forma correta para usar diferentes funções. Depois de ter dados organizados, normalmente o próximo passo é transformá-los. A transformação inclui focar em observações de interesse (como todas as pessoas em uma cidade ou todos os dados do último ano), criar novas variáveis que são funções de variáveis existentes (como calcular a velocidade a partir da distância e do tempo) e calcular um conjunto de estatísticas resumidas (como contagens ou médias). Juntos, organizar e transformar são chamados de manipulação de dados2.
Uma vez que você tenha dados organizados e com as variáveis de que precisa, existem duas principais fontes de geração de conhecimento: visualização e modelagem. Essas têm pontos fortes e fracos complementares, portanto, qualquer análise de dados real irá iterar entre elas muitas vezes.
Visualização é uma atividade fundamentalmente humana. Uma boa visualização mostrará coisas que você não esperava ou levantará novas questões sobre os dados. Uma boa visualização também pode sugerir que você está fazendo a pergunta errada ou que precisa coletar dados diferentes. As visualizações podem surpreender você, mas não escalam particularmente bem porque exigem que um ser humano as interprete.
Modelos são ferramentas complementares à visualização. Depois de tornar suas perguntas suficientemente precisas, você pode usar um modelo para respondê-las. Os modelos são fundamentalmente ferramentas matemáticas ou computacionais, então geralmente escalam bem. Mesmo quando não o fazem, geralmente é mais barato comprar mais computadores do que comprar mais cérebros! No entanto, cada modelo faz suposições, e, por sua própria natureza, um modelo não pode questionar suas próprias suposições. Isso significa que um modelo não pode, fundamentalmente, surpreendê-lo.
A última etapa da ciência de dados é a comunicação, uma parte absolutamente crítica de qualquer projeto de análise de dados. Não importa o quão bem seus modelos e visualizações tenham ajudado você a entender os dados, a menos que você também possa comunicar seus resultados para outras pessoas.
Em torno de todas essas ferramentas está a programação. A programação é uma ferramenta abrangente que é usada em quase todas as partes de um projeto de ciência de dados. Não é necessário ser uma pessoa especialista em programação para ter sucesso na ciência de dados, mas aprender mais sobre programação compensa, pois se tornar melhor em programação permite automatizar tarefas comuns e resolver novos problemas com maior facilidade.
Você usará essas ferramentas em todos os projetos de ciência de dados, mas para a maioria deles, elas não são suficientes. Há uma regra aproximada de 80/20 em jogo: você pode abordar cerca de 80% de cada projeto usando as ferramentas que aprenderá neste livro, mas precisará de outras ferramentas para lidar com os 20% restantes. Ao longo deste livro, indicaremos recursos onde você pode aprender mais.
Como este livro está organizado
A descrição anterior das ferramentas da ciência de dados está organizada aproximadamente de acordo com a ordem em que você as utiliza em uma análise (embora, é claro, você vá iterar por elas várias vezes). Em nossa experiência, no entanto, aprender primeiro a importação e organização de dados não é a melhor escolha, porque essas tarefas são, 80% do tempo, rotineiras e entediantes, e nos outros 20% do tempo, são estranhas e frustrantes. Esse não é um bom ponto de partida para aprender um novo assunto! Em vez disso, começaremos com a visualização e transformação de dados que já foram importados e organizados. Dessa forma, quando você importar e organizar seus próprios dados, sua motivação permanecerá alta, porque você sabe que o esforço vale a pena.
Dentro de cada capítulo, procuramos seguir um padrão consistente: começar com alguns exemplos motivadores para que você possa entender o panorama geral e, em seguida, aprofundar nos detalhes. Cada seção do livro é acompanhada de exercícios para ajudar você a praticar o que aprendeu. Embora possa ser tentador pular os exercícios, a melhor maneira de aprender é praticando com problemas reais.
O que você não aprenderá
Existem vários tópicos importantes que este livro não aborda. Acreditamos que é importante manter um foco rigoroso no essencial para que você possa começar o mais rápido possível. Isso significa que não é possível, neste livro, abordar todos os tópicos importantes.
Modelagem
A modelagem é extremamente importante para a ciência de dados, mas é um tópico amplo e, infelizmente, não temos espaço suficiente para abordá-lo adequadamente aqui. Para aprender mais sobre modelagem, recomendamos fortemente o livro Tidy Modeling with R, escrito por nossos colegas Max Kuhn e Julia Silge. O livro Tidy Modeling with R ensinará a você a família de pacotes tidymodels, que, como você pode imaginar pelo nome, compartilha muitas convenções com os pacotes do tidyverse que usamos neste livro.
Big data
Este livro orgulhosamente e principalmente foca em conjuntos de dados pequenos e que cabem na memória3 (in-memory).
Este é o lugar certo para começar, porque você não poderá lidar com big data a menos que já tenha experiência com bases de dados pequenas. As ferramentas que você aprenderá ao longo da maior parte deste livro lidarão facilmente com centenas de megabytes de dados e, com um pouco de cuidado, você geralmente poderá usá-las para trabalhar com alguns gigabytes de dados. Também mostraremos como obter dados de bancos de dados e arquivos parquet, ambos frequentemente usados para armazenar big data. Você não necessariamente conseguirá trabalhar com o conjunto de dados inteiro, mas isso nem sempre é um problema, pois, em muitos casos, você só precisa de um subconjunto ou uma amostra para responder à pergunta que te interessa.
Se você está rotineiramente lidando com dados maiores (digamos, de 10 a 100 GB), recomendamos aprender mais sobre o pacote data.table. Não o ensinamos aqui porque ele usa uma interface diferente do tidyverse e requer que você aprenda algumas convenções diferentes. No entanto, ele é incrivelmente mais rápido, e o retorno no desempenho compensa o tempo investido para aprender a usá-lo, se você estiver trabalhando com big data.
Python, Julia e outros
Neste livro, você não aprenderá nada sobre Python, Julia ou qualquer outra linguagem de programação útil para a ciência de dados. Isso não é porque achamos que essas ferramentas são ruins. Elas não são! E, na prática, a maioria das equipes de ciência de dados usa uma combinação de linguagens, muitas vezes pelo menos R e Python. Mas acreditamos firmemente que é melhor dominar uma ferramenta de cada vez, e R é um ótimo ponto de partida.
Pré-requisitos
Fizemos algumas suposições sobre o que você já deveria saber para aproveitar ao máximo este livro. Você deve ter uma compreensão geral de matemática e é útil se você já tiver alguma experiência básica em programação. Se você nunca programou antes, pode achar o livro Hands on Programming with R, escrito por Garrett, um recurso valioso para complementar este livro.
Você precisará de quatro coisas para executar os códigos deste livro: R, RStudio, um conjunto de pacotes R chamado tidyverse e alguns outros pacotes. Pacotes são as unidades fundamentais de código R reprodutível. Eles incluem funções reutilizáveis, documentação que descreve como usá-los e dados de exemplo.
R
Para baixar o R, acesse o CRAN, o comprehensive R archive network, em https://cloud.r-project.org. Uma nova versão principal do R é lançada anualmente, e há 2-3 lançamentos menores a cada ano. É uma boa ideia atualizar regularmente. A atualização pode ser um pouco complicada, especialmente para as versões principais que exigem que você reinstale todos os seus pacotes, mas adiá-la só torna as coisas piores. Recomendamos o R 4.2.0 ou posterior para este livro.
RStudio
O RStudio é uma IDE (ambiente de desenvolvimento integrado), para programação em R, que você pode baixar em https://posit.co/download/rstudio-desktop/. O RStudio é atualizado algumas vezes por ano e ele o informará automaticamente quando uma nova versão estiver disponível, portanto, não é necessário verificar periodicamente. É uma boa ideia atualizar regularmente para aproveitar os recursos mais recentes e melhorados. Para este livro, certifique-se de ter pelo menos o RStudio 2022.02.0.
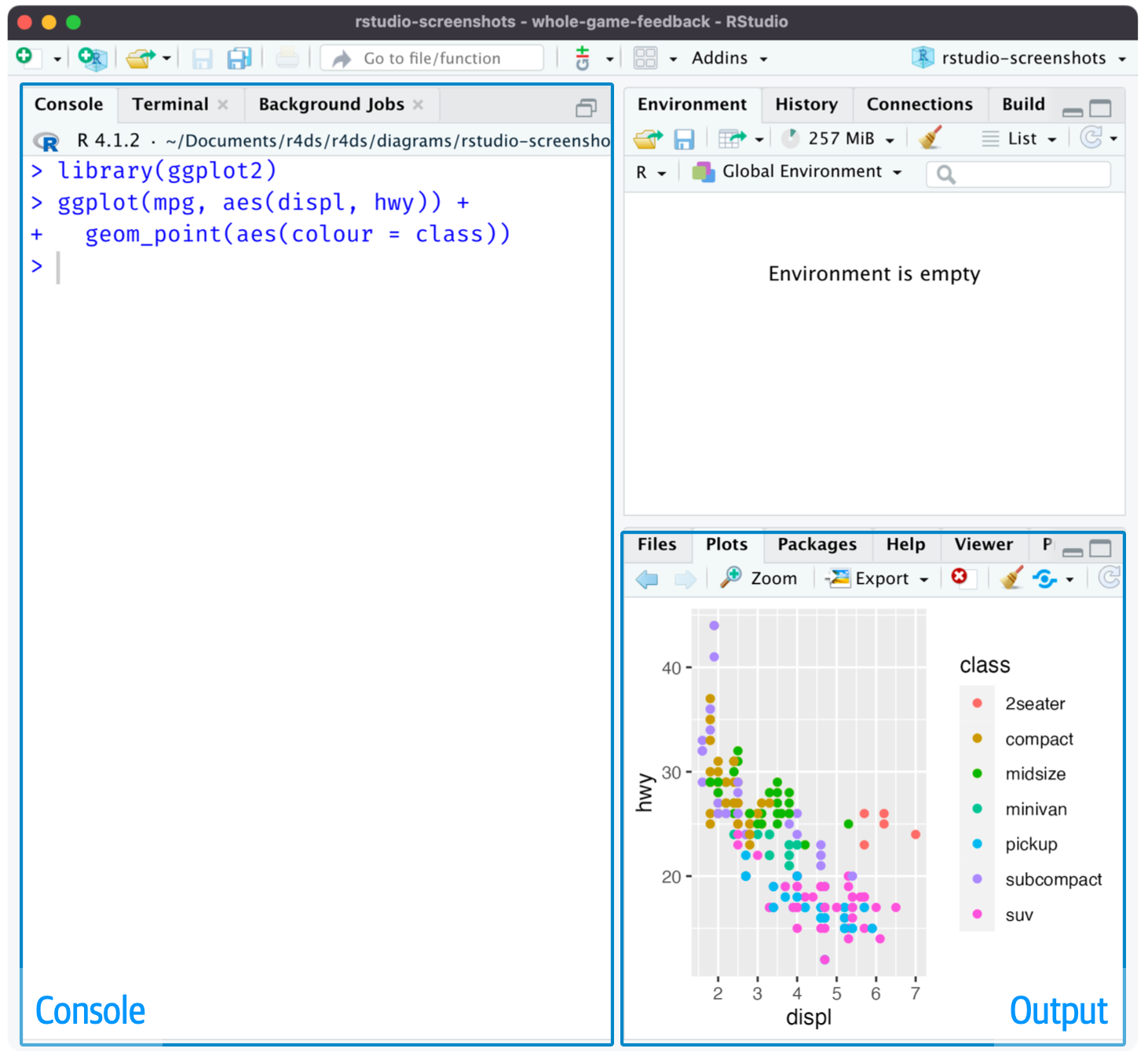
Quando você inicia o RStudio, Figura O RStudio possui duas partes principais: digite o código em R no Console à esquerda e procure o painel Plots dentro do painel Output à direita., você verá duas partes principais na interface: o painel de console (Console) e o painel de saída (Output). Por enquanto, tudo o que você precisa saber é que você digita o código R no Console e pressiona Enter para executá-lo. Você aprenderá mais à medida que avançarmos!4
O tidyverse
Você também precisará instalar alguns pacotes do R. Um pacote do R é uma coleção de funções, dados e documentação que estende as capacidades do R base. O uso de pacotes é fundamental para o uso bem-sucedido do R. A maioria dos pacotes que você aprenderá neste livro faz parte do chamado tidyverse. Todos os pacotes no tidyverse compartilham uma filosofia comum de dados e programação em R e são projetados para funcionar juntos.
Você pode instalar o tidyverse completo com uma única linha de código:
install.packages("tidyverse")Em seu computador, digite essa linha de código no console e pressione Enter para executá-la. O R fará o download dos pacotes do CRAN e os instalará em seu computador.
Você não poderá usar as funções, objetos ou arquivos de ajuda de um pacote até carregá-lo com library(). Depois de instalar um pacote, você pode carregá-lo usando a função library():
library(tidyverse)
#> ── Attaching core tidyverse packages ───────────────────── tidyverse 2.0.0 ──
#> ✔ dplyr 1.1.4.9000 ✔ readr 2.1.5
#> ✔ forcats 1.0.0 ✔ stringr 1.5.1
#> ✔ ggplot2 3.5.1 ✔ tibble 3.2.1
#> ✔ lubridate 1.9.3 ✔ tidyr 1.3.1
#> ✔ purrr 1.0.2
#> ── Conflicts ─────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsIsso informa que o tidyverse carrega nove pacotes: dplyr, forcats, ggplot2, lubridate, purrr, readr, stringr, tibble, tidyr. Esses são considerados o núcleo do tidyverse porque você os usará em quase todas as análises.
Os pacotes do tidyverse mudam com bastante frequência. Você pode verificar se há atualizações disponíveis executando tidyverse_update().
Outros pacotes
Existem muitos outros pacotes excelentes que não fazem parte do tidyverse porque resolvem problemas em um domínio diferente ou são projetados com um conjunto diferente de princípios subjacentes. Isso não os torna melhores ou piores; apenas os torna diferentes. Em outras palavras, o complemento ao tidyverse não é o messyverse5, mas muitos outros universos de pacotes inter-relacionados.
Conforme você enfrenta mais projetos de ciência de dados com R, aprenderá novos pacotes e novas formas de pensar sobre dados.
Usaremos muitos pacotes de fora do tidyverse neste livro. Por exemplo, usaremos os seguintes pacotes porque eles fornecem conjuntos de dados interessantes para trabalharmos no processo de aprendizado do R:
install.packages(
c("arrow", "curl", "remotes", "duckdb",
"ggrepel", "ggridges", "ggthemes", "hexbin", "janitor",
"leaflet", "maps", "openxlsx",
"repurrrsive", "tidymodels", "writexl")
)
# Instalar o pacote de dados
remotes::install_github("cienciadedatos/dados")Também usaremos uma seleção de outros pacotes para exemplos isolados. Você não precisa instalá-los agora, apenas lembre-se de que sempre que vir um erro como este:
Você precisará executar install.packages("ggrepel") para instalar o pacote.
Executando código em R
A seção anterior mostrou vários exemplos de execução de código em R. O código no livro parece assim:
1 + 2
#> [1] 3Se você executar o mesmo código no seu console, ele parecerá assim:
> 1 + 2
[1] 3Existem duas diferenças principais. No seu console, você digita após o >, chamado de prompt; não mostramos o prompt no livro. No livro, a saída é comentada com #>; no seu console, ela aparece diretamente após o código. Essas duas diferenças significam que se você estiver trabalhando com uma versão online do livro, poderá copiar facilmente o código do livro e colá-lo no console.
Ao longo do livro, usamos um conjunto consistente de convenções para se referir ao código:
Funções são exibidas em uma fonte de código e seguidas por parênteses, como
sum()oumean().Outros objetos R (como dados ou argumentos de função) estão em uma fonte de código, sem parênteses, como
voosoux.Às vezes, para deixar claro de qual pacote um objeto vem, usaremos o nome do pacote seguido por quatro-pontos
::, comodplyr::mutate()oudados::voos. Isso também é código em R válido.
Agradecimentos
Este livro não é apenas o produto de Hadley, Mine e Garrett, mas é o resultado de muitas conversas (pessoalmente e online) que tivemos com muitas pessoas na comunidade R. Estamos incrivelmente gratos por todas as conversas que tivemos com todos vocês; muito obrigado!
Este livro foi escrito de forma colaborativa e muitas pessoas contribuíram por meio de pull requests. Um agradecimento especial a todas as 259 pessoas que contribuíram com melhorias por meio de pull requests no GitHub (em ordem alfabética pelo nome de usuário): @a-rosenberg, Tim Becker (@a2800276), Abinash Satapathy (@Abinashbunty), Adam Gruer (@adam-gruer), adi pradhan (@adidoit), A. s. (@Adrianzo), Aep Hidyatuloh (@aephidayatuloh), Andrea Gilardi (@agila5), Ajay Deonarine (@ajay-d), @AlanFeder, Daihe Sui (@alansuidaihe), @alberto-agudo, @AlbertRapp, @aleloi, pete (@alonzi), Alex (@ALShum), Andrew M. (@amacfarland), Andrew Landgraf (@andland), @andyhuynh92, Angela Li (@angela-li), Antti Rask (@AnttiRask), LOU Xun (@aquarhead), @ariespirgel, @august-18, Michael Henry (@aviast), Azza Ahmed (@azzaea), Steven Moran (@bambooforest), Brian G. Barkley (@BarkleyBG), Mara Averick (@batpigandme), Oluwafemi OYEDELE (@BB1464), Brent Brewington (@bbrewington), Bill Behrman (@behrman), Ben Herbertson (@benherbertson), Ben Marwick (@benmarwick), Ben Steinberg (@bensteinberg), Benjamin Yeh (@bentyeh), Betul Turkoglu (@betulturkoglu), Brandon Greenwell (@bgreenwell), Bianca Peterson (@BinxiePeterson), Birger Niklas (@BirgerNi), Brett Klamer (@bklamer), @boardtc, Christian (@c-hoh), Caddy (@caddycarine), Camille V Leonard (@camillevleonard), @canovasjm, Cedric Batailler (@cedricbatailler), Christina Wei (@christina-wei), Christian Mongeau (@chrMongeau), Cooper Morris (@coopermor), Colin Gillespie (@csgillespie), Rademeyer Vermaak (@csrvermaak), Chloe Thierstein (@cthierst), Chris Saunders (@ctsa), Abhinav Singh (@curious-abhinav), Curtis Alexander (@curtisalexander), Christian G. Warden (@cwarden), Charlotte Wickham (@cwickham), Kenny Darrell (@darrkj), David Kane (@davidkane9), David (@davidrsch), David Rubinger (@davidrubinger), David Clark (@DDClark), Derwin McGeary (@derwinmcgeary), Daniel Gromer (@dgromer), @Divider85, @djbirke, Danielle Navarro (@djnavarro), Russell Shean (@DOH-RPS1303), Zhuoer Dong (@dongzhuoer), Devin Pastoor (@dpastoor), @DSGeoff, Devarshi Thakkar (@dthakkar09), Julian During (@duju211), Dylan Cashman (@dylancashman), Dirk Eddelbuettel (@eddelbuettel), Edwin Thoen (@EdwinTh), Ahmed El-Gabbas (@elgabbas), Henry Webel (@enryH), Ercan Karadas (@ercan7), Eric Kitaif (@EricKit), Eric Watt (@ericwatt), Erik Erhardt (@erikerhardt), Etienne B. Racine (@etiennebr), Everett Robinson (@evjrob), @fellennert, Flemming Miguel (@flemmingmiguel), Floris Vanderhaeghe (@florisvdh), @funkybluehen, @gabrivera, Garrick Aden-Buie (@gadenbuie), Peter Ganong (@ganong123), Gerome Meyer (@GeroVanMi), Gleb Ebert (@gl-eb), Josh Goldberg (@GoldbergData), bahadir cankardes (@gridgrad), Gustav W Delius (@gustavdelius), Hao Chen (@hao-trivago), Harris McGehee (@harrismcgehee), @hendrikweisser, Hengni Cai (@hengnicai), Iain (@Iain-S), Ian Sealy (@iansealy), Ian Lyttle (@ijlyttle), Ivan Krukov (@ivan-krukov), Jacob Kaplan (@jacobkap), Jazz Weisman (@jazzlw), John Blischak (@jdblischak), John D. Storey (@jdstorey), Gregory Jefferis (@jefferis), Jeffrey Stevens (@JeffreyRStevens), 蒋雨蒙 (@JeldorPKU), Jennifer (Jenny) Bryan (@jennybc), Jen Ren (@jenren), Jeroen Janssens (@jeroenjanssens), @jeromecholewa, Janet Wesner (@jilmun), Jim Hester (@jimhester), JJ Chen (@jjchern), Jacek Kolacz (@jkolacz), Joanne Jang (@joannejang), @johannes4998, John Sears (@johnsears), @jonathanflint, Jon Calder (@jonmcalder), Jonathan Page (@jonpage), Jon Harmon (@jonthegeek), JooYoung Seo (@jooyoungseo), Justinas Petuchovas (@jpetuchovas), Jordan (@jrdnbradford), Jeffrey Arnold (@jrnold), Jose Roberto Ayala Solares (@jroberayalas), Joyce Robbins (@jtr13), @juandering, Julia Stewart Lowndes (@jules32), Sonja (@kaetschap), Kara Woo (@karawoo), Katrin Leinweber (@katrinleinweber), Karandeep Singh (@kdpsingh), Kevin Perese (@kevinxperese), Kevin Ferris (@kferris10), Kirill Sevastyanenko (@kirillseva), Jonathan Kitt (@KittJonathan), @koalabearski, Kirill Müller (@krlmlr), Rafał Kucharski (@kucharsky), Kevin Wright (@kwstat), Noah Landesberg (@landesbergn), Lawrence Wu (@lawwu), @lindbrook, Luke W Johnston (@lwjohnst86), Kara de la Marck (@MarckK), Kunal Marwaha (@marwahaha), Matan Hakim (@matanhakim), Matthias Liew (@MatthiasLiew), Matt Wittbrodt (@MattWittbrodt), Mauro Lepore (@maurolepore), Mark Beveridge (@mbeveridge), @mcewenkhundi, mcsnowface, PhD (@mcsnowface), Matt Herman (@mfherman), Michael Boerman (@michaelboerman), Mitsuo Shiota (@mitsuoxv), Matthew Hendrickson (@mjhendrickson), @MJMarshall, Misty Knight-Finley (@mkfin7), Mohammed Hamdy (@mmhamdy), Maxim Nazarov (@mnazarov), Maria Paula Caldas (@mpaulacaldas), Mustafa Ascha (@mustafaascha), Nelson Areal (@nareal), Nate Olson (@nate-d-olson), Nathanael (@nateaff), @nattalides, Ned Western (@NedJWestern), Nick Clark (@nickclark1000), @nickelas, Nirmal Patel (@nirmalpatel), Nischal Shrestha (@nischalshrestha), Nicholas Tierney (@njtierney), Jakub Nowosad (@Nowosad), Nick Pullen (@nstjhp), @olivier6088, Olivier Cailloux (@oliviercailloux), Robin Penfold (@p0bs), Pablo E. Garcia (@pabloedug), Paul Adamson (@padamson), Penelope Y (@penelopeysm), Peter Hurford (@peterhurford), Peter Baumgartner (@petzi53), Patrick Kennedy (@pkq), Pooya Taherkhani (@pooyataher), Y. Yu (@PursuitOfDataScience), Radu Grosu (@radugrosu), Ranae Dietzel (@Ranae), Ralph Straumann (@rastrau), Rayna M Harris (@raynamharris), @ReeceGoding, Robin Gertenbach (@rgertenbach), Jajo (@RIngyao), Riva Quiroga (@rivaquiroga), Richard Knight (@RJHKnight), Richard Zijdeman (@rlzijdeman), @robertchu03, Robin Kohrs (@RobinKohrs), Robin (@Robinlovelace), Emily Robinson (@robinsones), Rob Tenorio (@robtenorio), Rod Mazloomi (@RodAli), Rohan Alexander (@RohanAlexander), Romero Morais (@RomeroBarata), Albert Y. Kim (@rudeboybert), Saghir (@saghirb), Hojjat Salmasian (@salmasian), Jonas (@sauercrowd), Vebash Naidoo (@sciencificity), Seamus McKinsey (@seamus-mckinsey), @seanpwilliams, Luke Smith (@seasmith), Matthew Sedaghatfar (@sedaghatfar), Sebastian Kraus (@sekR4), Sam Firke (@sfirke), Shannon Ellis (@ShanEllis), @shoili, Christian Heinrich (@Shurakai), S’busiso Mkhondwane (@sibusiso16), SM Raiyyan (@sm-raiyyan), Jakob Krigovsky (@sonicdoe), Stephan Koenig (@stephan-koenig), Stephen Balogun (@stephenbalogun), Steven M. Mortimer (@StevenMMortimer), Stéphane Guillou (@stragu), Sulgi Kim (@sulgik), Sergiusz Bleja (@svenski), Tal Galili (@talgalili), Alec Fisher (@Taurenamo), Todd Gerarden (@tgerarden), Tom Godfrey (@thomasggodfrey), Tim Broderick (@timbroderick), Tim Waterhouse (@timwaterhouse), TJ Mahr (@tjmahr), Thomas Klebel (@tklebel), Tom Prior (@tomjamesprior), Terence Teo (@tteo), @twgardner2, Ulrik Lyngs (@ulyngs), Shinya Uryu (@uribo), Martin Van der Linden (@vanderlindenma), Walter Somerville (@waltersom), @werkstattcodes, Will Beasley (@wibeasley), Yihui Xie (@yihui), Yiming (Paul) Li (@yimingli), @yingxingwu, Hiroaki Yutani (@yutannihilation), Yu Yu Aung (@yuyu-aung), Zach Bogart (@zachbogart), @zeal626, Zeki Akyol (@zekiakyol).
Considerações Finais
A versão online deste livro está disponível em https://cienciadedatos.github.io/pt-r4ds/. O código fonte do livro está disponível em https://github.com/cienciadedatos/pt-r4ds. O livro é gerado pelo Quarto, que facilita a escrita de livros que combinam texto e código executável.
Nota de tradução: tidy é um verbo em inglês que quer dizer “arrumar/organizar”. Tidy data é uma forma de organizar os dados, que será abordado no capítulo 5 ✅ Organização de dados (data tidying).↩︎
Nota de tradução: Manipulação de dados é chamado em inglês de data wrangling, porque colocar seus dados em uma forma natural de trabalhar frequentemente parece uma luta (wrangle)!↩︎
Nota de tradução: “Caber na memória” se refere à memória RAM (random access memory) do computador, cuja função é guardar temporariamente toda a informação que o computador precisa (por exemplo, as bases de dados importadas).↩︎
Se você deseja uma visão abrangente de todos os recursos do RStudio, consulte o Guia de uso do RStudio em https://docs.posit.co/ide/user.↩︎
Nota de tradução: tidyverse é a união das palavras tidy (arrumado) e universe (universo), sendo então a ideia de um “universo arrumado”. messy quer dizer desarrumado, e messyverse seria a ideia de um universo desarrumado.↩︎